ChatGPT 의 등장 이후 LLM 의 인기가 어마어마하다. 필자의 개인적인 생각으로는 2015년 알파고의 파급력보다 ChatGPT 의 파급력이 더 크다고 생각한다.
많은 Tech 기업에서는 자체 기술력으로 LLM 을 만들고 서비스할 수 있다고 광고하고 있다.
본 포스팅에서는 LLM 을 어떻게 학습할 수 있는지, 학습 방법 별 특징은 무엇인지 설명한다.
필자는 LLM 을 효율적으로 활용하기 위해서는 학습 방법을 이해해야 한다고 생각한다.
인공지능 모델은 학습한대로 예측하는 경향성을 띄기 때문이다.
※ 글에서 언급하는 단어에 혼동이 있을 수 있습니다.
- ['인공지능 모델', 'Generation 모델', '모델'] 이라는 표현은 모두 ChatGPT 와 같은 LLM 을 의미합니다.
- ['Input', 'Input text'] 의 의미는 LLM 에 들어가는 글(=text)을 의미합니다.
- ['Output', 'Output text'] 의 의미는 LLM 에서 Input 을 계산하여 나오는 모델의 결과(=text) 를 의미합니다.
LLM 이란?
Large Language Model 의 줄인말인 LLM 은 한국어로 초거대 언어 모델이라고도 한다. 그럼 각각의 단어가 상징하는 의미에 대해 알아보자.

'Large' 의 뜻은 모델의 크기가 크다는 의미로 크기의 지표는 모델이 가진 Parameter(=Weight) 를 뜻한다. Parameter 란 쉽게 말하면 중학교 수학에서 배우는 함수(=f(x))에서 x의 계수, 상수를 뜻한다. x의 계수, 상수가 엄청나게 많기 때문에 Large 를 붙였다. 현재 암묵적으로 Large 의 기준은 100B(=1000억) 이상의 Parameter 수인 것 같다.
(근거: Parameter 의 수가 3B~70B 인 LLM 을 sLLM(=small Large Language Model) 이라고 하기 때문)
'Language' 의 뜻은 인공지능 모델이 언어를 다룬다는 의미이다. 인공지능 모델은 함수와 같이 input 과 output 으로 구성된다. 함수로 비유하면 input 은 `y = f(x)` 에서 `x` 를 뜻하고 output 은 `y` 를 뜻한다. Language 의 의미는 input 인 `x` 와 output 인 `y` 가 모두 언어(=text)로 구성되어 있다는 의미이다.
'Model' 의 뜻은 인공지능 구조를 뜻한다. 인공지능 구조는 단순하게 함수라고도 말할 수 있다. 인공지능 모델은 Parameter 의 조합으로 구성되어 있다. 앞서 설명한 내용과 같이 Parameter 는 함수에서 변하지 않는 x의 계수, 상수와도 같기 때문에 동일한 input 이 들어가면 동일한 output 이 나오게 되어 있다. 때문에 Model 은 f(x) 라고 생각하면 된다.
그렇다면 왜 이렇게 많은 Parameter 로 구성된 LLM 이 탄생하게 되었을까? 그건 필자가 포스팅한 글을 참고하길 바란다.
LLM 을 학습하는 방법
Pre-Training
LLM 은 다른 LM(ex. BERT, GPT-2, ...)과 마찬가지로 사전학습(=Pre-Training)부터 시작한다.
사전학습이란 쉽게 말해 인공지능 모델이 다양한 지식을 배울 수 있도록 가르쳐주는 과정이다. 사람이 초등학교, 중학교, 고등학교에서 다양한 지식을 공부하여 학습하듯 인공지능 모델도 기본적인 정보들을 알 수 있도록 공부시킨다.
LLM 은 보통 Generation 모델이기 때문에 CLM 을 통해 학습한다. Generation 과 CLM 을 예시로 설명하겠다.
크리스마스 또는 성탄절은 예수의 탄생을 기리는 날로, 날짜는 매년 12월 25일이다.
from 위키피디아 크리스마스 검색 결과
위 문장을 인공지능 모델에게 공부시킨다고 해보자.
1. 인공지능 모델은 위키피디아 크리스마스 검색 결과 를 학습하고자 한다.
2. 모델은 `크리스마스` 를 예측했다.
3. 모델은 `크리스마스` 를 보고 그 다음 text 인 `또는` 을 예측했다.
4. 모델은 `크리스마스 또는` 을 보고 그 다음 text 인 `성탄절은` 을 예측했다.
5. 이 과정을 반복한다.
이와 같이 사전학습에서는 이전 text 를 보고 이후 text 를 Generation 하는 CLM 방법이 사용된다. 이 학습 방법을 Next Token Prediction 이라고 말한다. 이러한 학습을 수 많은 문장에 대해 수행하여 다양한 지식을 공부시키는 방법이다.
물론 이 방법에는 치명적인 단점이 존재한다. 다음에 나올 text 를 예측하다보면 잘못된 정보가 output 이 될 수 있기 때문이다. 이를 할루시네이션이라고 한다.


스타크래프트 하이템플러의 기술처럼 진짜가 아닌 무언가를 생성하는 걸 의미하는 할루시네이션은 ChatGPT 의 등장 전까지 Generation 모델의 흥행을 막는 치명적인 단점이 되었다. 잘못된 정보는 곧 서비스화 적용 시 치명적인 오류로 이어지기 때문이다.
지금까지 설명한 사전학습을 정리하면 다음과 같다.
- 인공지능 모델이 폭 넓은 지식을 알 수 있도록 가르치는 학습 방법이다.
- 요즘 런칭되는 대부분의 LLM 은 Generation 모델이다.
- Generation 모델은 CLM 을 통해 학습한다.
- CLM 은 이전의 text 를 기반으로 다음에 올 text 를 예측하는 학습 방법이다.
- CLM 학습 방법에 의해 사전학습 Generation 모델은 할루시네이션 이슈가 있다.
- 할루시네이션이란 진짜가 아닌 가짜 정보를 생성하는 문제를 말한다.
이제 할루시네이션 단점을 최소화하고자 사전학습 모델을 추가로 학습시키는 방법을 소개하겠다.
Supervised Fine-Tuning
사전학습을 통해 인공지능 모델에게 폭 넓은 지식을 가르친 후에 SFT(=Supervised Fine-Tuning) 를 통해 좁고 깊은 지식을 가르친다.

예를들어 대학교 석박 과정과 같이 좁고 깊은 지식을 공부해서 어떤 분야의 전문가가 되는 학습 방법이 SFT 다.
요즘 SFT 로 많이 사용되는 학습 방법 중 하나는 Instruction Finetuning 이다. 이 방법은 Prompt 를 사용한 학습 방법인데 Prompt 란 Generation 모델인 LLM 에게 어떤 행동을 해야 하는지 Text 로 설명하고 원하는 output 을 얻을 수 있도록 하는 방식이다. Prompt 의 예시를 통해 더 알아보자.
- Prompt 사용했을 때
Input
당신은 AI 연구원입니다.
당신은 전문가가 아닌 사람도 이해할 수 있는 수준으로 답변해야 합니다.
질문: Generation 모델에 대해 설명해줄래?
Output
이런저런 답변답변답변
- Prompt 사용하지 않았을 때
Input
Generation 모델에 대해 설명해줄래?
Output
이런저런 답변답변답변
Prompt 를 통해 인공지능 모델이 Output 을 만들 때 Generation 모델에 대해 더 쉽게 설명하는 text 를 만들어줄 수 있다.
지금까지 설명한 SFT 의 특징을 정리하면 다음과 같다.
- 사전학습 모델의 단점인 할루시네이션 문제가 발생할 확률을 낮출 수 있다.
- 특정 분야에 대한 지식을 학습시켜 인공지능 모델을 전문가로 만들 수 있다.
- 최근 많이 사용하는 SFT 의 방법은 Prompt 를 활용한 Instruction Finetuning 이다.
- Prompt 를 통해 원하는 모델의 결과를 얻을 수 있는 확률을 높여준다.
물론 SFT 의 단점도 있다.
- 학습 데이터셋을 만드는데 많은 리소스가 필요하다. (리소스: 시간, 돈)
- 인공지능 모델에게 모범 답안만 학습시킬 수 있다. (=학습 데이터셋에 다양한 상황을 반영할 수 없다.)
- 인공지능 모델에게 이 답변은 하면 안 된다는 정보를 학습시킬 수 없다.
- A 답변보다는 B 답변이 좋아. 라는 정보를 학습시킬 수 없다.
- 학습하지 않은 데이터(=input&output)에 대해서는 성능이 떨어질 수 있다.
이러한 단점을 해결하기 위해 등장한 학습 방법이 RLHF 이다. RLHF 는 SFT 의 단점인 2번을 상당 부분 해결하여 인공지능 모델의 성능을 높여주는 역할을 했다. (1번, 3번 이슈를 해결하기 위해서는 다른 방법이 사용된다. 본 포스팅에서는 다루지 않는다. 만약 궁금하다면 RLAIF, DPO 를 검색해보길 바란다.)
여기서 주의할 점은 RLHF 학습을 하기 위해서는 SFT 를 거친 n 개의 모델이 필요하다는 것이다. 이 내용은 복잡한 이론을 가졌기 때문에 본 포스팅에서는 다루지 않겠다. 만약 궁금하다면 GPT-3.5 기술 리포트를 참고하길 바란다.
Reinforcement Learning from Human Feedback
너무너무 유명한 ChatGPT 에서 사용한 방법으로 RLHF 라 줄여 말한다. 이 개념을 이해하기 위해서는 강화학습에 대해 먼저 알아야 한다.
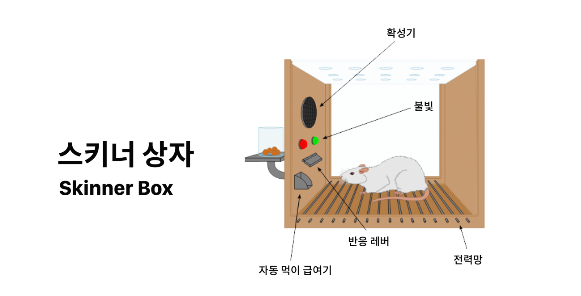
강화학습은 유명한 심리 실험인 스키너의 쥐 실험을 떠올리면 쉽게 이해할 수 있다. 스키너의 쥐 실험은 다음과 같다.
- 스키너 상자(=닫힌 공간)에 배고픈 상태의 쥐를 넣는다.
- 쥐는 스키너 상자를 돌아다니다가 우연히 지렛대를 누르게 된다.
- 지렛대를 누르자 먹이가 나온다.
- 지렛대와 먹이의 상관관계를 모르는 쥐는 다시 상자 안을 돌아다닌다.
- 다시 우연히 지렛대를 누른 쥐는 또 먹이가 나오는 것을 보고 지렛대를 누르는 행위를 자주 한다.
- 이러한 과정이 반복되면서 쥐는 지렛대를 누르면 먹이가 나온다는 사실(지렛대와 먹이의 상관관계)을 학습한다.
쥐는 어떤 환경(= 스키너 상자)에서 특정한 상황(=배고픔)에 특정한 행위(=지렛대를 누르는)를 하면 보상(=먹이)이 주어짐을 점차 학습하게 되고 보상을 강화(=반복)하려 한다. 이것이 바로 강화학습의 기본 개념이다. 이렇게 비유하여 추가 설명하겠다.
- 쥐 : 인공지능 모델
- 환경(=스키너 상자) : 인공지능 모델에게 가르치고자 하는 좁고 깊은 지식의 환경(⊃ Domain)
- 상황(=배고픔) : 인공지능 모델에 input 으로 들어가는 text
- 행위(=지렛대를 누르는) : 인공지능 모델의 결과(=output)
- 보상(=먹이) : 인공지능 모델의 결과를 평가(평가를 기반으로 모델을 학습한다.)
- 보상을 강화(=반복)하는 과정이 바로 인공지능 모델의 결과를 개선하기 위한 업그레이드 과정이다.
이 비유를 풀어서 글로 설명하면 다음과 같다.
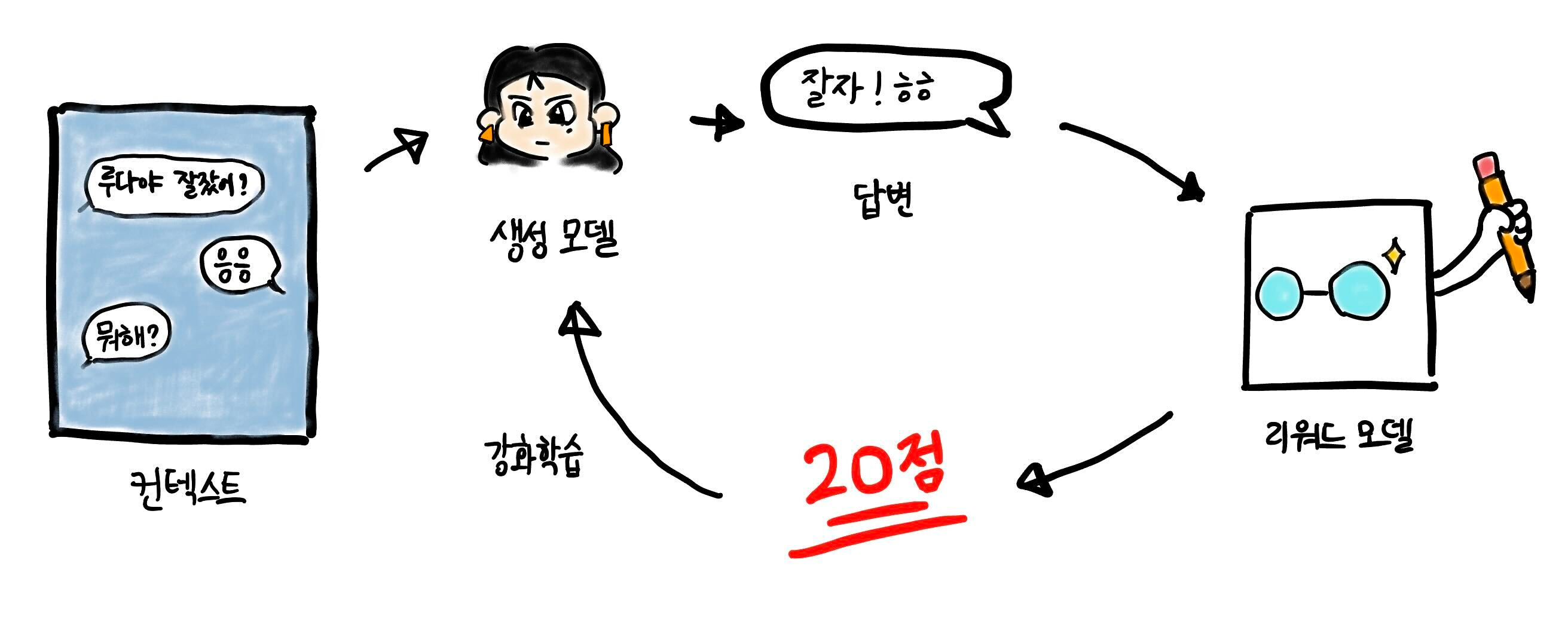
- 인공지능 모델은 좁고 깊은 지식(=환경)을 학습하기 위해서 Input 이 들어가면(=상황) Output 이 나오는 행위를 반복한다.
- Output 을 사용자가 원하는 방식으로 추출하기 위해 Input 이 들어갈 때마다 "Output 의 형태는 이래야해.!!" 라는 걸 가르친다(=강화)
- Output 의 형태는 사용자가 사전에 정의해둔 n 개의 답변에 사람의 선호도를 추가하여 선호도가 높은 답변을 인공지능 모델이 배워 다음부터는 높은 선호도의 답변을 Output 으로 출력(=보상)할 수 있도록 한다.
- 예를들어 Input 이 "나 오늘 저녁으로 뭘 먹을까?" 라고 해보자.
- 학습하고자 하는 Output 의 형태는 사용자가 사전에 정의해둔 n 개의 답변을 활용한다.
- n 개의 답변은 다음과 같다. (n=3 이라 가정)
a. "나는 빨간색을 좋아해"
b. "혹시 돈까스 어때? 돈까스는 언제 먹어도 맛있잖아.!"
c. "지금 저녁 메뉴 선택할때니? 샐러드나 먹어"
- n 개의 답변은 다음과 같다. (n=3 이라 가정)
- n 개의 답변에 사람이 판단한 선호도를 정의한다.
ex) 선호도 순위: b > c > a - 인공지능 모델은 "나 오늘 저녁으로 뭘 먹을까?" 가 input 으로 들어가면 output 으로 b 가 나오도록, a 가 나오지 않도록 학습한다.
- 학습이 완료되면 인공지능 모델은 보상이 높은 행위를 수행하고자 한다. 이를 통해 할루시네이션 문제를 해결하고 사용자가 원하는 형태의 답변을 얻을 수 있는 확률을 높인다.
이제 Reinforcement Learning from Human Feedback 에서 단어 별 의미를 알아보자.
- Reinforcement Learning : 보상을 강화하도록 학습하는 방법
- Human Feedback : 사람이 사전에 정의해둔 선호도
즉, 사람이 사전에 직접 Input 에 대한 Output 선호도를 정하여 모델이 선호도가 높은 Output 을 배울 수 있도록 보상 점수를 활용하여 학습하는 방법을 RLHF 라 말한다.
지금까지 설명한 RLHF 의 특징을 정리하면 다음과 같다.
- 강화학습을 기반으로 인공지능 모델을 학습한다.
- 학습 데이터는 사람이 직접 Feedback 한 Input 에 대한 Output(=text) 이다.
- 인공지능 모델은 "이런 답변을 해야 돼.!" 뿐만 아니라 "이런 답변은 하면 안 돼.!" 라는 정보도 함께 학습한다.
- 다른 말로 표현하면 "A 답변보다는 B 답변이 좋아.!" 라는 정보를 학습한다고도 할 수 있다.
RLHF 에도 단점이 있다.
- 학습 데이터셋을 만드는데 많은 리소스가 필요하다. (리소스: 시간, 돈)
- 학습하지 않은 데이터(=input&output)에 대해서는 성능이 떨어질 수 있다.
- RLHF 학습을 위해서는 n 개의 인공지능 모델이 필요하다.
- 해당 n 개의 인공지능 모델을 활용하여 RLHF 하기 위해서는 많은 리소스가 필요하다. (리소스: 서버의 스펙, 비용, 학습 시간 등)
- RLHL 학습의 불안정성이 있다.
- 보상을 측정하기 위해서 보상 측정 용도로 학습한 인공지능 모델을 활용한다.
- 보상 측정 인공지능 모델의 성능이 좋지 않으면 학습이 제대로 이루어지지 않는다.
(자세한 이슈는 리워드 해킹 or mode collapse 검색 추천)
여전히 SFT 에서 언급한 일부 단점을 해결하지 못한다. 뿐만 아니라 다른 Side Effect 가 발생할 수 있다.
물론 전 세계의 뛰어난 연구원들은 이 단점을 극복하기 위한 실험을 진행하고 있다.
해당 실험은 본 포스팅에서는 다루지 않겠다. 궁금하면 아래 키워드를 검색하여 확인하길 바란다.
- 키워드: Rejection Sampling, PRHF, DPO, RLAIF
마무리,,
ChatGPT 의 영향력에 의한 대 LLM 의 시대에 살아남기 위해서는 어떤 직무든 LLM 을 효율적으로 잘 사용해야 한다.
LLM 을 효율적으로 잘 사용하기 위해서는 어떤 학습 방법을 통해 LLM 이 만들어졌는지 알아야 된다고 생각한다.
왜냐하면 학습 방법은 LLM 이 어떻게 Output 을 만드는지에 관한 근거가 담겨있기 때문이다.
이러한 근거를 토대로 어떻게 Input 을 넣어줘야 내가 원하는 형식의 Output 이 나오는지를 예상할 수 있다.
내가 원하는 형식의 Output 이 나와야 자신이 속한 직무에서 LLM 을 적절하게 그리고 효율적으로 활용할 수 있다.
다음 포스팅에서는 내가 원하는 형식의 Output 이 나오도록 유도하는 방법인 RAG(= Retrieval-Augmented Generation)과 Prompt 팁, COT(= Chain-of-thought ) 그리고 ICL(= In-Context Learning )에 대해 다루도록 하겠다.
'Natural Language Processing > NLG 이모저모' 카테고리의 다른 글
| LLAMA 모델 구조 파악 (1) | 2024.01.08 |
|---|---|
| LLM 학습을 위한 데이터 생성에 대하여,, (0) | 2023.12.29 |
| ChatGPT Prompt 작성 팁 (2) | 2023.12.27 |
| LLM 의 할루시네이션을 줄이는 방법 (1) | 2023.12.27 |
| [소개] 초거대 언어 모델이란? (0) | 2022.07.16 |




댓글