들어가며..
최근 여러 대기업에서 자신들이 만든 초거대 언어 모델을 소개하며 홍보하는 걸 자주 접할 수 있다. 물론 해당 분야에 관심이 있는 사람들만 접할 수 있었겠지만 본 포스팅을 읽는 독자들은 접했으리라 믿는다. 대기업들은 왜 초거대 언어 모델을 만드는지, 왜 초거대 언어 모델이 필요한지, 초거대 언어 모델의 장점은 무엇인지 본 포스팅에서 소개하도록 하겠다.
초거대 언어 모델이란?
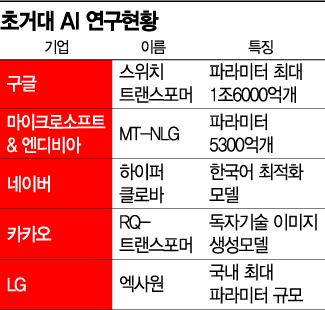
AI라고 부르는 인공지능은 간단히 말하면 일종의 함수(y = f(x))이다. 챗봇을 예로 들면 발화자의 말이 text로 변환되어 함수의 x로 들어가 인공지능이라는 함수 내부에서 여러 계산이 이루어진다. 계산의 결과는 y로 발화자의 말에 대답하는 text가 된다. 그렇다면 왜 여러 대기업에서 파라미터가 5,000 억개, 1조 6,000 억개나 되는 초거대 언어 모델을 만드는 걸까? 그리고 파라미터가 5,000 억개라는게 얼마나 큰 걸까?
먼저 파라미터 5,000 억개가 얼마나 큰 것인지 설명하도록 하겠다. 파라미터 5,000 억개인 모델을 학습하기 위해서는 굉장히 좋은 성능의 device가 여러 개 필요하다. 여기서 device 란 cpu, gpu와 같은 컴퓨팅 계산을 담당하는 장치와 ssd와 같이 거대한 데이터를 저장, 관리할 수 있는 저장 장치를 뜻한다. 좋은 성능의 device 구성을 위해서는 최소 1억 원 이상의 금액이 필요하다. (가격의 관점에서만 비교한다면)우리가 사용하는 컴퓨터 보다 최소 100배는 좋은 컴퓨터가 필요하다고 생각하면 된다.
그렇다면 초거대 언어 모델은 왜 만드는 걸까? 여러 이유가 있겠지만 가장 큰 이유는 다양한 목적에 맞게 응용하여 사용하고자 할 때 모든 task에서 좋은 성능을 보인다는 점이다. 이것은 사전 학습(Pre-train)과 전이 학습(Fine-tune) 덕분에 가능하다.
'사전 학습이란 다양한 목적에 맞게 사용하기 위해 전반적인 지식을 가르치는 과정이다.'
'전이 학습이란 사전 학습된 모델을 내가 원하는 목적에 맞게 특수화 시켜주는 과정이다.'
사전 학습과 전이 학습을 다음 비유를 보며 알아보자.
'B' 씨는 영어 통번역학과를 다니는 석사 과정 학생이다. 'B' 씨는 지인에게 토익 강사를 제안 받는다. 'B' 씨는 토익 강사가 되기 위해 토익 공부를 한다. 만약 'B' 씨가 수학과를 다니는 석사 과정 학생이라면 토익 강사가 되기 위한 공부의 시간이 얼마나 걸릴까? 또한 강사가 된다한들 잘 가르칠 수 있을까?
이것이 바로 사전 학습과 전이 학습이다. 사전 학습은 영어를 공부하는 'B' 씨처럼 영어에 대해 전반적인 지식을 학습(=공부)하는 과정이다. 전이 학습은 특정 task를 집중적으로 학습(=토익 강사가 되기 위해 공부)하는 과정이다.
당연히 수학과를 다니는 학생보다 영어 통번역학과를 다니는 학생이 토익을 가르치기 더 좋은 조건일 것이다.
언어 모델의 크기가 크다는 것은 'B' 씨의 전반적인 영어 실력이 뛰어나다는 말이다. 즉, 초거대 언어 모델은 영어 통번역학과 교수라고도 할 수 있다. 만약 교수가 토익 강사를 하고자 한다면 강사가 되기 위한 준비 과정이 간단할 뿐 아니라 강사로서 좋은 실력을 보일 것이라 기대할 수 있을 것이다. 만약 교수가 번역 일을 하고자 한다면 이 또한 간단한 준비 과정과 좋은 성과를 기대할 수 있을 것이다. 이처럼 초거대 언어 모델의 장점은 다양한 task(or 다양한 산업군)에서 사전 학습된 모델을 전이 학습 시켜 사용할 때 좋은 성능을 기대할 수 있다는 점이다. 이것이 많은 대기업에서 초거대 언어 모델을 만드는 이유이다.
필자의 의견
초거대 언어 모델을 만들기 위해 환경을 구성하는 것은 쉽지 않다. 많은 돈이 필요하고, 환경을 관리할 관리자도 필요하기 때문이다. 필자가 생각하는 어려운점은 초거대 언어 모델의 사용에 있다. 많은 기업들은 요즘 발표되는 초거대 언어 모델보다 작은 모델인 BERT(2018년 10월 논문) 모델도 사용하기 부담스러워 한다. 기업이 인공지능 기술을 도입할 때 체크하는 사항 중 하나가 바로 인공지능 도입 전 후 기대 비용의 차이이기 때문이다. 초거대 언어 모델을 도입하기 위한 환경 셋팅에 드는 비용보다 간단한 Rule logit으로 관리하는 게 더 효율적이라면 초거대 언어 모델을 도입할 필요가 없다.
많은 기업이 초거대 언어 모델을 사용하기까지는 아직 시간이 필요하다. 하지만 많은 연구자들은 어떻게 작은 자원으로 거대 모델을 사용할 수 있을까?를 고민하며 연구하고 있다.
다음 포스팅에서는 거대 언어 모델을 다루기 위한 방법 중 하나인 Deep Learning Compiler에 대해 살펴볼 것이다.
To Be Continued
https://beeny-ds.tistory.com/20
[소개] Deep Learning Compiler 란?
들어가며.. 현대를 살아는 대부분의 사람들이 자주 접하는 AI 기술은 챗봇이지 않을까? 챗봇 기술은 대부분 작은 기기에 내장되어 동작한다. 우리가 흔히 접할 수 있는 예로는 '인공지능 스피커
beeny-ds.tistory.com
'Natural Language Processing > NLG 이모저모' 카테고리의 다른 글
| LLAMA 모델 구조 파악 (1) | 2024.01.08 |
|---|---|
| LLM 학습을 위한 데이터 생성에 대하여,, (0) | 2023.12.29 |
| ChatGPT Prompt 작성 팁 (2) | 2023.12.27 |
| LLM 의 할루시네이션을 줄이는 방법 (1) | 2023.12.27 |
| LLM 학습에 대한 고찰 (1) | 2023.12.26 |




댓글