이전 포스팅에서는 'LLM 을 학습하기 위해 어떻게 학습 데이터를 만들어야 하는지' 에 관해 소개했다.
이번 포스팅은 Backbone 이 되는 LLM 으로 가장 많이 활용되는 LLAMA 모델의 구조에 대해 알아보도록 하겠다.
※ NLP 전문가 Level 의 연구자에게 도움이 되는 글임을 유의하길 바란다.
목차
- Model Architecture
- a. LlamaModel 구조
- i. Embedding Layer
- ii. Decoder Layer
- b. CausalLM Layer
- a. LlamaModel 구조
- 참고 문서
1. Model Architecture
a. LlamaModel 구조
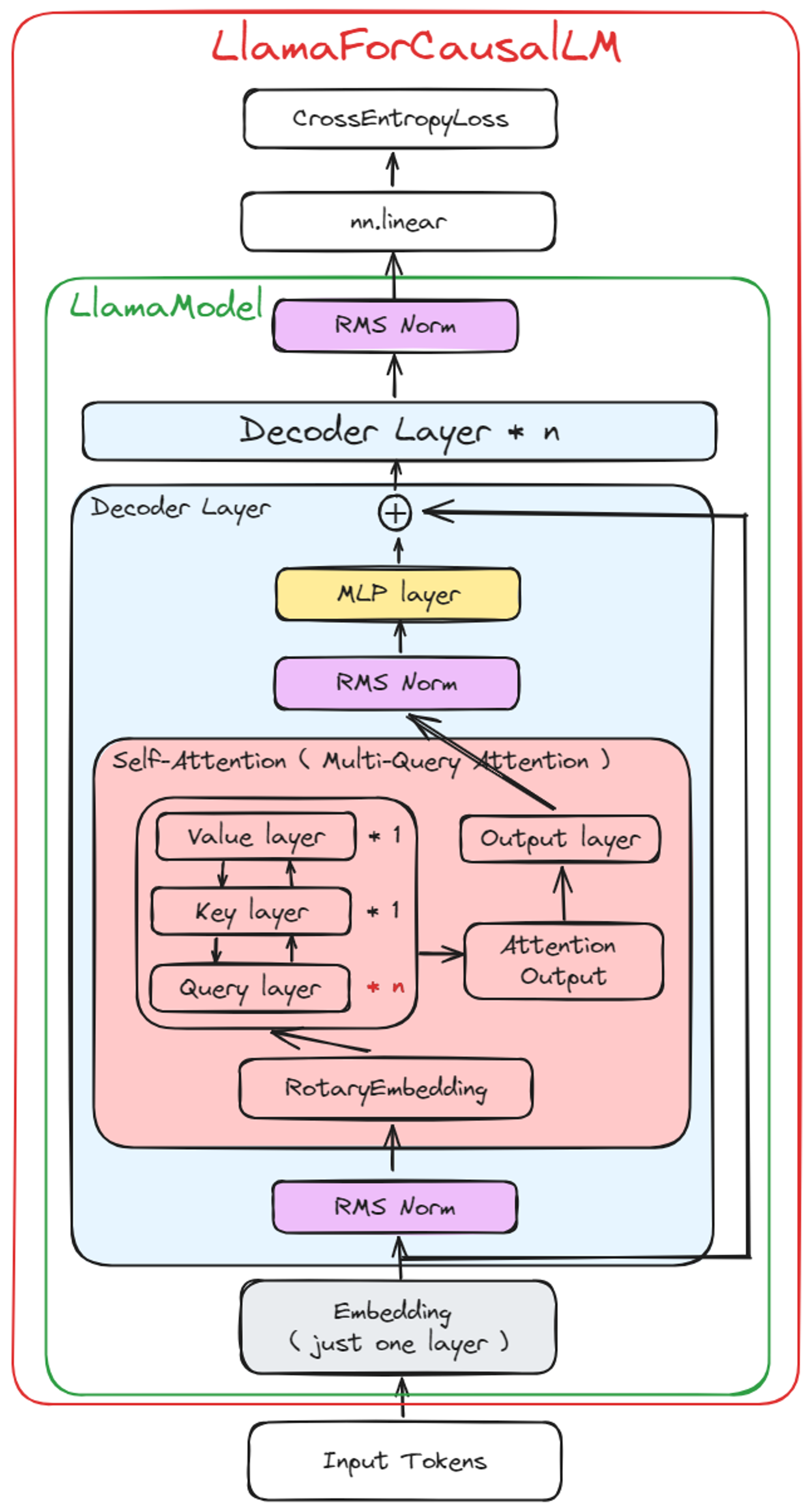
i. Embedding Layer
- nn.embeding 하나만 사용한다.
- Encoder 모델의 Embedding layer 와 다르다.
- Encoder 모델의 Embedding 에서는 3개의 nn.embedding 사용
ii. Decoder Layer
- RotaryEmbedding (Full Name: Rotary Positional Embeddings)
- 특징
- BERT 에서 사용한 절대적은 Positional Embedding 제거
- 매 Layer 마다 Position 값을 주입하여 Sinusoidal Positional Embedding 의 단점을 해결
- 자세한 내용은 추후 포스팅 예정
- 특징
- MLP Layer
- 특징 : Encoder 모델의 { Intermediate layer } 와 비슷한 역할을 함
- 3 개의 nn.linear 를 사용 (a.k.a gate projection, up projection, down projection)
- 3 개의 linear 를 마치 attention_score 를 구하는 것과 동일한 로직으로 연산을 함
- Input 차원과 Output 차원 모두 hidden_size 차원과 같음
- 내부 계산은 hidden_size 차원 만큼의 행렬을 만들어 계산 (hidden_size x hidden_size matrix)
- 특징 : Encoder 모델의 { Intermediate layer } 와 비슷한 역할을 함
- Self-Attention (eg. Multi-Query Attention, Grouped-Query Attention)
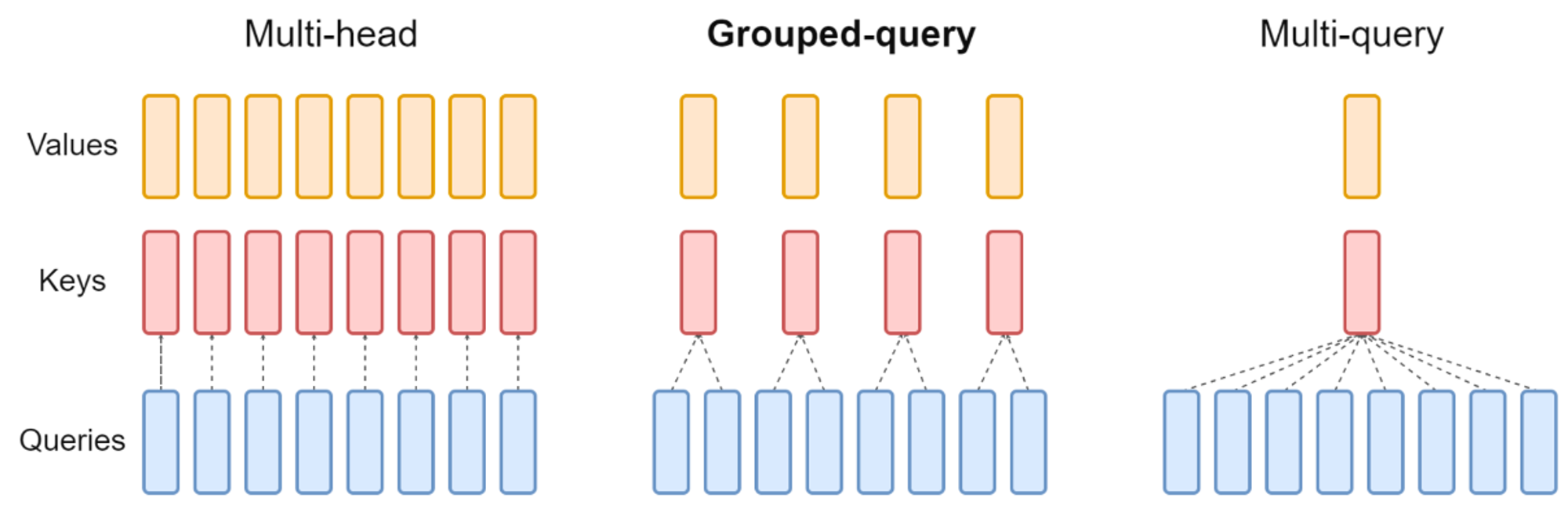
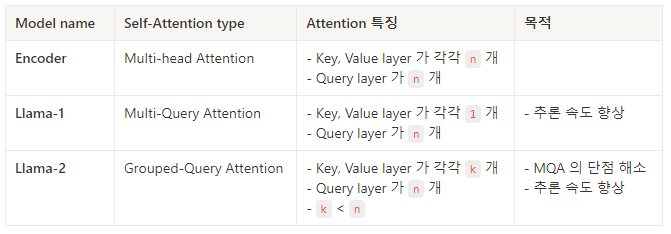
첨언: Self-Attention 에 있는 Output Layer 의 역할은 Attention 값을 보정하는 것으로 추측된다.
- 특징: input dim & output dim 이 같다. (hidden_size 로 동일)
b. CausalLM Layer
- 특징: loss 계산을 위해 logit score 와 label vector 를 cut 하며 계산
- 흔한 CLM 과 동일한 사상을 가짐
2. 참고 문서
- LLaMA 2
- Rotary Embeddings
- Grouped Query Attention
마무리,,
LLM 구조를 자세히 뜯어본적은 처음이다. 실은 Decoder 모델의 동작 원리만 알았지 상세 내용은 모르고 있었다.
이번 기회에 LLM 구조를 확인해보니 어떤 방향으로 LLM 에 대해 공부해야 할지 리서치해야 할지 느낌이 온다.
하여 다음 포스팅에서는 ALiBi 에 대해 알아볼 예정이다.
추가로 Rotary Positional Embedding 까지 알아보도록 하겠다.
반응형
'Natural Language Processing > NLG 이모저모' 카테고리의 다른 글
| LLM 을 Pretrain 학습하려면,, (2) | 2024.01.25 |
|---|---|
| LLM 학습을 위한 데이터 생성에 대하여,, (0) | 2023.12.29 |
| ChatGPT Prompt 작성 팁 (2) | 2023.12.27 |
| LLM 의 할루시네이션을 줄이는 방법 (1) | 2023.12.27 |
| LLM 학습에 대한 고찰 (1) | 2023.12.26 |




댓글