미네소타 대학 2019년 7월 16일 논문 발간
Overview
💡 Transformer의 attention mechanism에 착안하여, 학생의 과거 학습 기록과 주어진 문제간의 연관성을 계산하여 정오답을 예측하는 모델.
- Knowledge concepts 간의 연관성을 이용
정오답을 예측하고자 하는 문제는 이전에 풀었던 문제들과 연관성을 고려하여 예측

가정: 5번 문제를 맞췄는지, 틀렸는지 예측하고자 할 때, 이전에 풀었던 문제들 중 4번 문제 및 2번 문제와 연관성이 크기 때문에 5번 문제에 대한 정오답 여부는 4번 문제와 2번 문제의 정오답 여부와 관련이 클 것이다.
- 이러한 개념을 Knowledge Concepts(a.k.a KCs)라고 함.

SAKT
💡 Deep Knowledge Tracing 모델에 최초로 Transformer Self-Attention을 사용한 모델
- 정오답을 예측하고자 하는 문제는 이전에 풀었던 문제들과 연관성을 고려하여 예측
- Masking 적용하여 현재 지점(t)을 예측함에 있어 앞의 시퀀스(t-1)에만 의존하도록 제한
- Masking을 적용하여 ($x_t, x_{t+1}, ... , x_{T}$)에 대한 정보가 고려되는 것을 방지
Model architecture


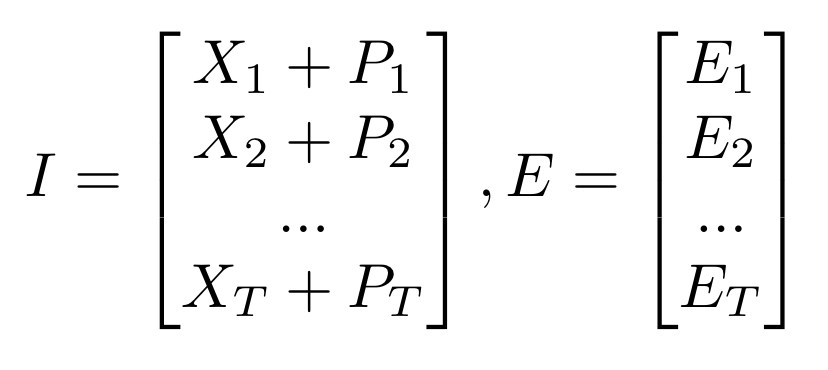
Input datasets
- E_t: t번째 문제 정보(e_t → Knowledge Concepts)에 대한 embedding vector
- X_t: e_t와 r_t로 구성된 x_t = (e_t, r_t) → vectorization
- 전체 문제의 개수를 N이라고 했을 때, e_t가 가질 수 있는 값의 개수 = N 개이고, r_t는 정답 혹은 오답이기 때문에 x_t가 가질 수 있는 값의 개수는 2N개
Embedding Layer
- P_t: t번째 position에 대한 정보를 나타낼 수 있는 positional embedding vector
- x_t가 가질 수 있는 값 2N개와 e_t가 가질 수 있는 값 N개 각각에 해당하는 embedding vector 존재
- x_t, e_t와 position t를 embedding vector로 mapping
Model output
- 학생이 문제를 푼 뒤, 정오답 정보(r_1, r_2, ... , r_{T})를 예측 → Sigmoid func 사용 즉, Model output은 정오답 확률
Model Performance
데이터셋 → Synthetic / ASSISTment 2009&2015&Chall / STATICS
💡 사람 별로 스킬에 대한 문제에 오정답 여부 포함
- user_id: 학생
- log_id: order to solve problems each students
- sequence_id: concept (=skill)
- correct: 정오답 유무
ASSISTmentsData
Professor Heffernan asks his graduate students to release their data and code to this website every time they publish a paper (as long as the data is %100 anonymized; we do have data sets that include student open response data where a student could releas
sites.google.com
https://sites.google.com/view/assistmentsdatamining/dataset?authuser=0
The 2017 ASSISTments Datamining Competition - Dataset
ASSISTments Data Mining Competition 2017 You can sign up to gain access to the dataset here. The link to your dataset will be sent to your email in a few minutes. The access to the dataset is free and you are allowed to publish paper on this dataset as lon
sites.google.com
결과
💡 2019년 7월까진 가장 좋은 성능을 보였다고.. 비교 모델은 RNN 계열 모델들..
References
- 논문 → link
- 논문 리뷰 → Knowledge Tracing을 위한 Attention Mechanism
- 배포된 코드
💡 학습 데이터가 뤼이드 데이터셋(=EdNet)이라고...
- 미네소타 대학에서 배포한 코드는 아님
- Mumbai University 딥러닝 개발자가 배포
- 모델 define만 해준 코드... 학습 및 평가 코드는 따로 짜줘야 됨. → 학습된 모델은 없음
https://github.com/arshadshk/SAKT-pytorch
GitHub - arshadshk/SAKT-pytorch: Implementation of paper "A Self-Attentive model for Knowledge Tracing"
Implementation of paper "A Self-Attentive model for Knowledge Tracing" - GitHub - arshadshk/SAKT-pytorch: Implementation of paper "A Self-Attentive model for Knowledge Tracing"
github.com
- 모델 학습 및 평가 코드 정리. but 에러가 날 수 있음.
https://github.com/TianHongZXY/pytorch-SAKT
GitHub - TianHongZXY/pytorch-SAKT: a simple pytorch implemention of paper A Self-Attentive model for Knowledge Tracing
a simple pytorch implemention of paper A Self-Attentive model for Knowledge Tracing - GitHub - TianHongZXY/pytorch-SAKT: a simple pytorch implemention of paper A Self-Attentive model for Knowledge ...
github.com
'Broad AI without NLP > Education' 카테고리의 다른 글
| [이모저모] 플랫폼을 만들기 위해서는 무엇이 필요 할까? (0) | 2022.08.24 |
|---|---|
| [Mathpresso] 콴다에서 AI 기술 활용 정리 (1) | 2022.08.24 |
| Knowledge Tracing datasets (0) | 2022.06.23 |
| [SAINT+] Integrating Temporal Features for EdNet Correctness Prediction (0) | 2022.06.23 |
| [SAINT] Towards an Appropriate Query, Key, and Value Computation for Knowledge Tracing (0) | 2022.06.23 |



댓글