Riiid AI Research team 2021년 2월 1일 논문 발간
Overview
💡 SAINT와 거의 유사하지만 추가적인 정보(input data)가 더 들어가 성능을 약 1% 향상시킴
- SAINT 모델 Overview와 같은 내용
- SAINT 모델 이전에 어텐센을 적용한 모델(ex. SAKT model)은 input 데이터(ex. IRT)의 복잡한 관계를 반영하지 못했다.
- SAINT 모델은 input 데이터의 적절한 활용을 제안하여 EdNet 데이터 셋(=KT 모델 관련 밴치마크 데이터셋)에 대해 좋은 성능을 보였다.
- SAINT 모델이 input 데이터를 활용하는 방법은 다음과 같다.
- Encoder-Decoder transformer architecture 사용
- 인코더에서 문제 관련된 정보를 사용
- 디코더에서 학생이 문제를 맞췄는지 틀렸는지 관련된 정보를 사용
SAINT+ 모델 → 추가된 내용
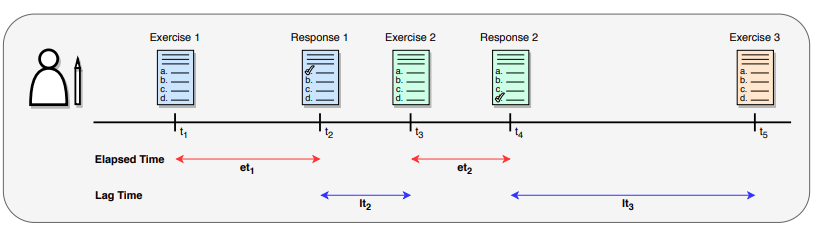
- SAINT+는 디코더 인풋에 2가지의 정보가 추가적으로 더 들어감
- Elapsed Time: 한 문제를 푸는데 걸린 시간
- Lag Time: 한 문제를 풀고 다음 문제를 시작하기 전까지 걸린 시간
SAINT+
💡 Model archi는 transformer encoder-decoder로 구성되어 있음.
- 인코더에서 문제 관련된 정보를 input으로 사용.
- 디코더에서 문제 정답 유무, 문제 푸는데 걸린 시간 정보를 input으로 사용.
Model architecture
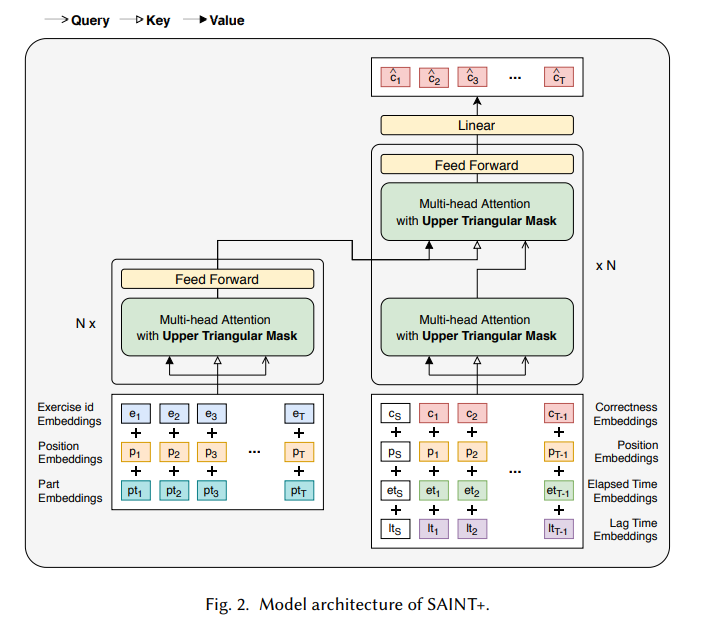
- Transformer encoder-decoder 구조
- [SAINT 모델과 동일] Q, K, V를 어떻게 사용할지 고민을 많이 했다고 함
- 실제 학생이 공부한다고 생각하며 구성. k번째 문제를 풀 때에는 k-1개의 문제 관련된 정보만 알고 있음
- K번째 문제를 맞췄는지 예측하기 위해 K-1개의 문제 embedding vector를 사용
- Masking을 적용하여 현재 지점(k)을 예측함에 있어 앞의 시퀀스(k-1)에만 의존하도록 제한
Input datasets

- Encoder
- Exercise ID: A latent vector is assigned to an ID unique to each exercise.
- Part: 각각의 exercise가 속하는 categoty. (= Exercise category)
- Position
- input sequence에 있는 exercise나 response의 위치. 포지션 임베딩은 exercise나 response 공유
- Decoder
- Position
- input sequence에 있는 exercise나 response의 위치. 포지션 임베딩은 exercise나 response 공유
- Correctness: 학생의 정오답 여부 1:정답, 0:오답 (= Response)
- Elapsed time: 한 문제를 푸는데 걸린 시간
- Lag time: 한 문제를 풀고 다음 문제를 시작하기 전까지 걸린 시간
- Position
Model output

- 새로운 exercise(문제)를 학생이 맞출지 여부를 예측
- Model output은 해당 exercise를 맞췄다 or 틀렸다로 나옴
Model Performance
데이터셋 → EdNet-KT1
💡 Android, iOS 및 웹을 통해 제공되는 한국의 780,000명 이상의 사용자가 있는 다중 플랫폼 AI 튜터링 서비스인 Santa에서 2년 동안 수집한 모든 학생 시스템 상호 작용의 데이터 세트
- 즉, articial intelligence tutoring system인 산타토익 어플에서 수집된 로그 데이터
https://github.com/riiid/ednet
GitHub - riiid/ednet: EdNet is the dataset of all student-system interactions collected over 2 years by Santa, a multi-platform
EdNet is the dataset of all student-system interactions collected over 2 years by Santa, a multi-platform AI tutoring service with more than 780K users in Korea available through Android, iOS and w...
github.com
결과
💡 기존 SOTA인 SAINT보다도 1% 가까운 성능 향상
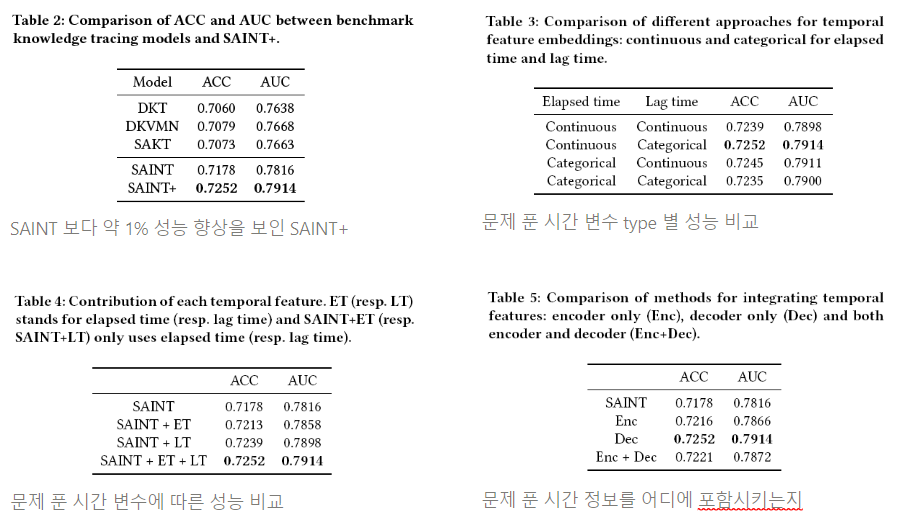
- 기존이 SOTA인 SAINT보다도 1% 가까운 성능 향상
- Ablation test
- Continuous vs Categorical
- 연속형 변수의 경우 et x weight로 사용
- 범주형 변수는 ET: 최대 300까지의 정수, LT: 0, 1, 2, 3, 4, 5, 10, 20, 30, ..., 1440의 총 150개의 unique latent vector 사용
- ET, LT 사용 여부에 따른 성능 차이
- 시간 정보를 어디에 포함시키는지
- Continuous vs Categorical
학습 환경에 관련된 정보를 추가하니 성능이 더 향상
References
논문 → link
배포된 코드
💡 SAINT+의 저자인 Riiid에서 공식적으로 공개한 pre-trained model이나 source code는 없음
- 다만 유저들이 직접 github, kaggle에 업로드한 것들은 찾을 수 있었음
- 어떤 코드가 괜찮은 코드인지 검토 필요
https://github.com/Shivanandmn/SAINT_plus-Knowledge-Tracing-
GitHub - Shivanandmn/SAINT_plus-Knowledge-Tracing-: Implementation of [SAINT+: Integrating Temporal Features for EdNet Correctne
Implementation of [SAINT+: Integrating Temporal Features for EdNet Correctness Prediction](https://arxiv.org/abs/2010.12042) - GitHub - Shivanandmn/SAINT_plus-Knowledge-Tracing-: Implementation of ...
github.com
https://www.kaggle.com/code/m10515009/saint-is-all-you-need-training-private-0-801/notebook
SAINT+ is all you need (Training) private 0.801
Explore and run machine learning code with Kaggle Notebooks | Using data from multiple data sources
www.kaggle.com
https://www.kaggle.com/code/shivanandmn/saint-training-using-pytorch-success-run/notebook
SAINT+ Training using PyTorch [success run]
Explore and run machine learning code with Kaggle Notebooks | Using data from Riiid Answer Correctness Prediction
www.kaggle.com
'Broad AI without NLP > Education' 카테고리의 다른 글
| [이모저모] 플랫폼을 만들기 위해서는 무엇이 필요 할까? (0) | 2022.08.24 |
|---|---|
| [Mathpresso] 콴다에서 AI 기술 활용 정리 (1) | 2022.08.24 |
| Knowledge Tracing datasets (0) | 2022.06.23 |
| [SAINT] Towards an Appropriate Query, Key, and Value Computation for Knowledge Tracing (0) | 2022.06.23 |
| [SAKT] A Self-Attentive model for Knowledge Tracing (0) | 2022.06.22 |



댓글