본 논문에서는 별도의 모델 재학습 없이 모델을 추론할 때 학습할 때의 Max_Length 보다 더 많은 Input Token 을 처리할 수 있는 방법을 제시했다. 이 방법을 줄여서 ALiBi 라 한다. Fine-Tuning 으로 사용되는 LLM 인 LLAMA-2 와 같은 NLG 모델이 ALiBi 와 같은 구조를 사용한다.
- 적용 모델: Generation Model (LLM 에 적용되어 사용되고 있음)
- 논문 링크: https://arxiv.org/pdf/2108.12409.pdf
목차
- 배경
- 문제 제기
- ALiBi 방법
- 모델의 구조
- 결론
- 참고 문헌
1. 배경
ALiBi 는 Positional Embedding Issue 인
Max Length 를 늘려주면 성능 하락이 발생하는 문제를 해결
기존 Transformer 모델이 사용하던 Positional Embedding 의 Issue 와 고도화 연구는 다음과 같다.
- 이슈-①: max length > 512 설정하여 학습&추론하면 연산 복잡도가 증가함에 따라 성능이 떨어지고 속도가 느려진다.
- 어떻게 max length 의 값을 크게 설정하면서 성능과 속도 문제를 해결할 수 있는지 연구가 진행됐다.
- 이슈-②: 모델 추론 시 max length 의 값은 모델 학습에서 사용한 최댓값까지만 설정할 수 있다.
- 모델 추론 시 학습에서 사용한 최대 max length 보다 더 큰 length 를 사용할 수 있도록 연구가 진행됐다.
ALiBi 논문은 모델의 구조를 변경하여 이슈를 해결하고자 했다.
- 모델의 구조는 최근 2년 동안 등장한 LLM 인 Decoder 모델에 적용되고 있다.
- ALiBi 는 Generation Model 을 기준으로 실험 및 결론 도출을 했음
2. 문제 제기
Max Length 값이 커지며 나타나는 이슈를 다루었다.
- attention layer 의 time & space complexity 가 높아진다. (quadratic)
- embedding size d 가 커짐으로써 embedding layer 의 time & space complexity 가 높아진다. (quadratic)
- positional sinusoidal embedding 에서도 문제가 발생한다.
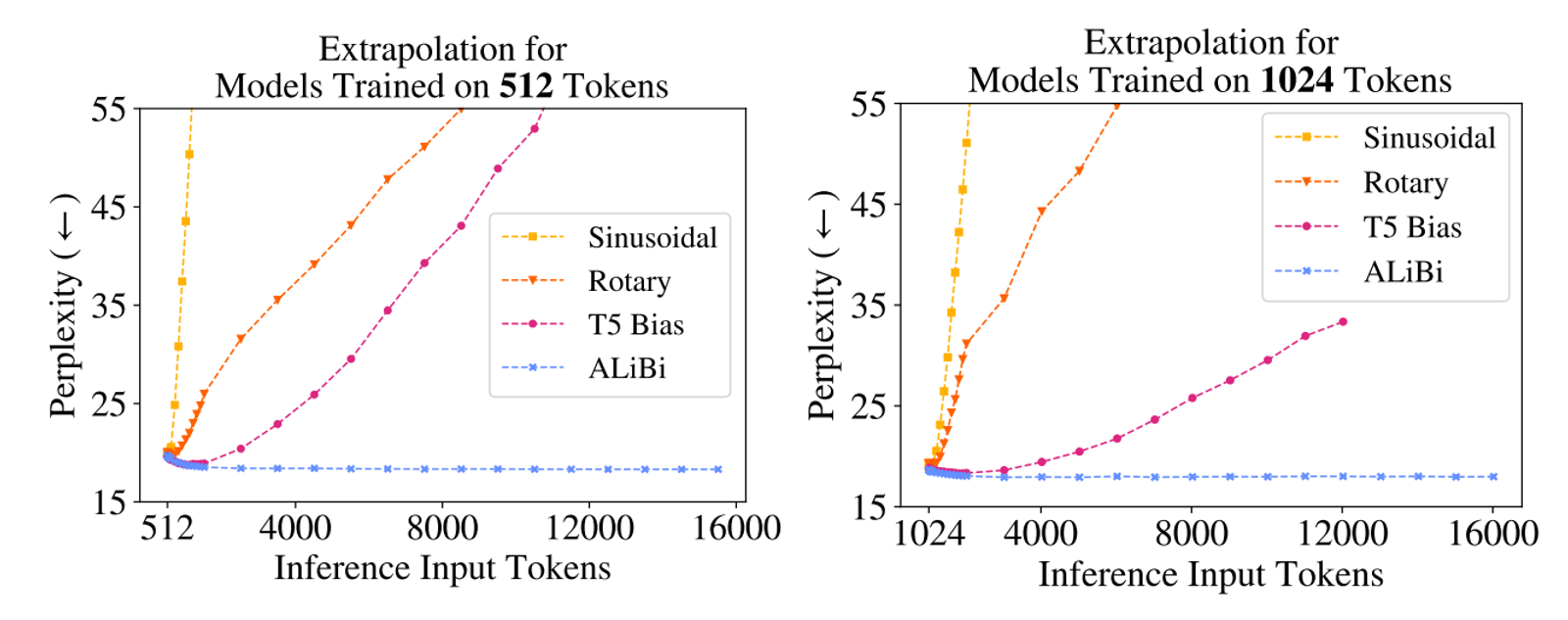
위 그래프는 Max Length = [512, 1024] Token 으로 학습한 모델 별 Input Tokens 에 따른 복잡성을 비교하였다.
위 그래프를 이해하기 위해서는 2가지를 알아야 한다.
바로 Perplexity 와 그래프 색을 표현한 Embedding 방법이다.
해당 그래프를 통해 알 수 있는 건 ALiBi 가 다른 3개의 방법에 비해 월등히 좋았다는 점이다.
- Perplexity 란 (a.k.a PPL)
- Text 생성 언어 모델의 성능 평가 지표로 낮을수록 언어 모델이 우수하다고 평가함
- Embedding 방법
- Sinusoidal : Sinusoidal Position Embeddings 를 뜻함
- Transformer 최초 모델에서 사용한 Position Embeddings. 학습되는 파라미터 없이 고정된 값을 사용하여 트랜스 포머의 첫 레이어에 더해준다.
- Rotary : Rotary Position Embeddings 를 뜻함 (a.k.a RoPE)
- GPT-J 에서 공개되어 유명해진 Position Embedding. Rotary method 를 사용해 매 레이어마다 포지션 값을 주입한다.
- T5 Bias
- T5 에서 제안된 Postion Embedding. Attention value 를 계산할 때 값을 수정하는 방법을 사용. 성능 향상은 있지만 학습 시간이 오래 걸리고 추가적인 메모리, 계산 비용이 필요하고, efficient transformer 들에 적용할 수 없다.
- ALiBi: Attention with Linear Biases 를 뜻함
- Releative Position Embedding(a.k.a RPE) 사상에서 시작한 본 논문의 Position Embedding.
- RoPE 와 같이 매 레이어마다 포지션 값을 주입한다.
- RoPE 와의 차이점은 Attention 을 구하는 공식의 차이에 있다.
- 논문 자료에 따르면 Transformer-XL 부터 Self-Attention 수식을 분해하여 RPE 를 분석 및 새로운 RPE 를 제안하는 논문들이 나왔다고 함..
- Sinusoidal : Sinusoidal Position Embeddings 를 뜻함
논문에서는 Input Length 에 따른 방법론 별 학습 및 추론 속도, VRAM 비용을 비교한 결과를 제시한다.
이 또한 ALiBi 방법이 우수하다고 한다.

위 그래프에서 알아야 할 것은 WPS 이다. (GB 는 다들 알거라 생각하므로 pass)
- WPS 란?
- Words Per Secode 의 약자로 단어의 처리량이다. 즉, 처리 속도를 함
- 을수록 속도가 빠르다고 평가함
그럼 모델의 구조를 기존 Transformer 의 Position Embedding 인 Sinusoidal 에서 어떻게 변경했기에 이러한 결과를 보일 수 있었을까?
3. ALiBi 방법
RPE 부터 모델의 구조를 변경시켜 기존 Embedding 인 Sinusoidal 방법의 한계를 극복하려는 연구가 진행되었다.
극복의 방향성은 다음과 같다.
- 모델을 학습할 때는 작은 Input Token n 으로 학습하고 추론할 때는 긴 Input Token N 을 가능하도록 모델 구조 변경 (n < N)
- 모델 추론 시 Input Token N 을 사용해도 성능 및 속도 하락이 없도록 Positional Embedding 방식 적용
변경된 모델의 구조는 다음과 같다.
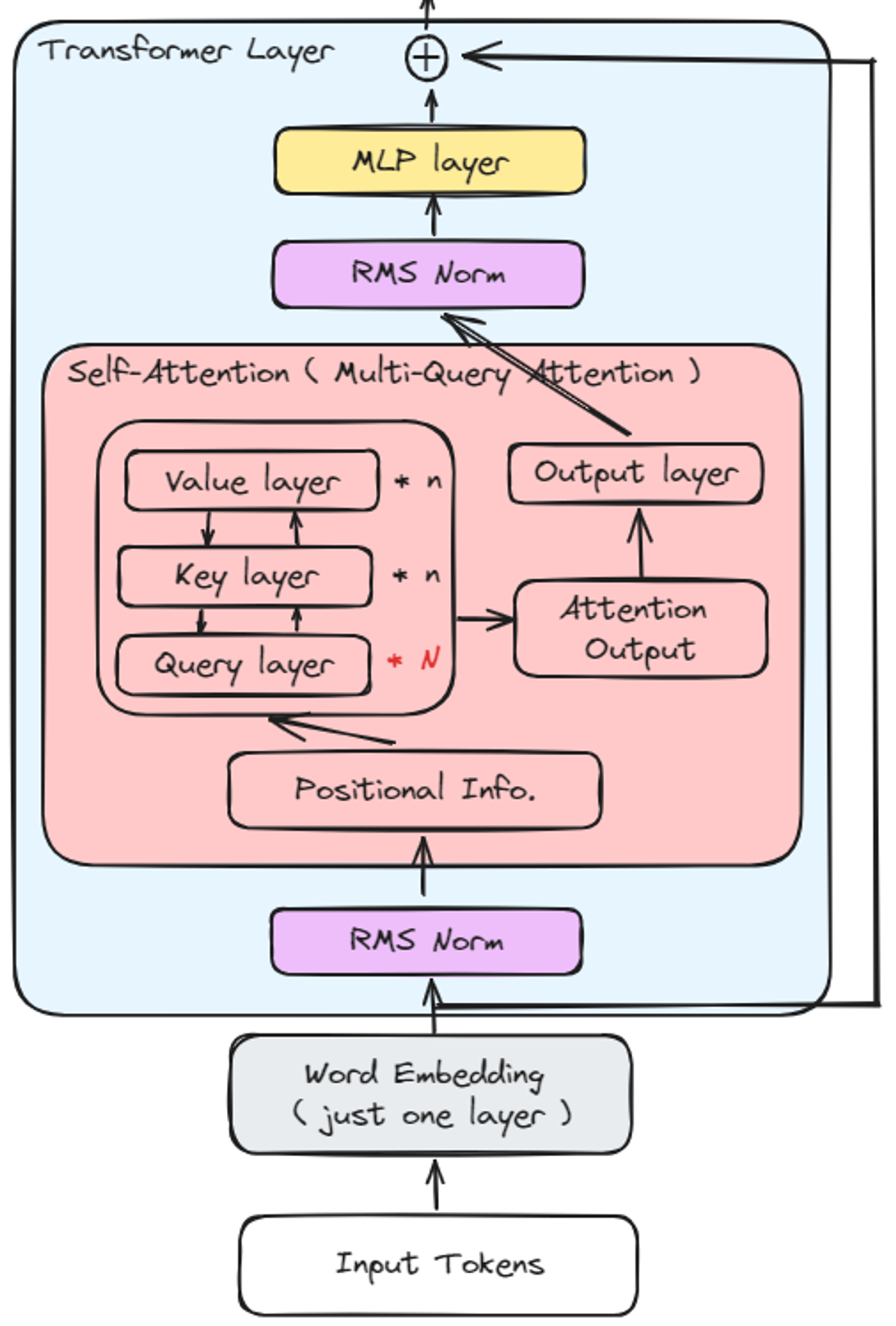
위 구조의 특징에 대해 알아보자.
- Positional Embedding Layer 삭제
- as-is: Embedding 에서는 3개의 Embeddings 을 사용했다. → [Word, Position, Token_type] Embeddings
- to-be: ( = ALiBi 방법 )
- Embedding Layer 에서 Input Token n 처리 시 Word Embedding 만 사용
- Token 들의 위치 정보는 Transformer Layer 안에 Positional Info.(=m) 를 Attention Score 값에 더해주는 방식 (Attention Score 가 Softmax 를 취하기 전에 거리에 따른 페널티 부여)
- positional Info.(=m) 라 표현한 이유는 layer 가 아닌 로지컬한 tensor 값이기 때문
- layer 가 아니기 때문에 Input Token n 의 값이 커도 위치 정보를 추가할 수 있음
- 로지컬 한 tensor detail: 여기서 n 은 attention head 의 개수
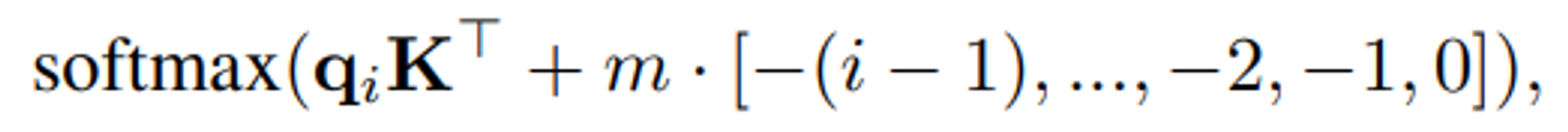
거리에 따라 패널티를 부여하는 방식으로 Score 값에 변형을 줌
- Sparse Attention Score 사용
- as-is: 모든 Token 들 사이의 Attention Score 계산
- to-be: ( = ALiBi 방법 )
- window 크기를 지정하여 window 내부에 있는 Token 간의 Attention pattern 만 고려
- 이를 통해 연산 복잡도가 증가할 방향이 quadratic 하지 않고 linear 하게 변경됨
- Flash Attention 사용
- 습과 추론에 걸리는 속도를 높이는 방법
- Multi-Query Attention 사용
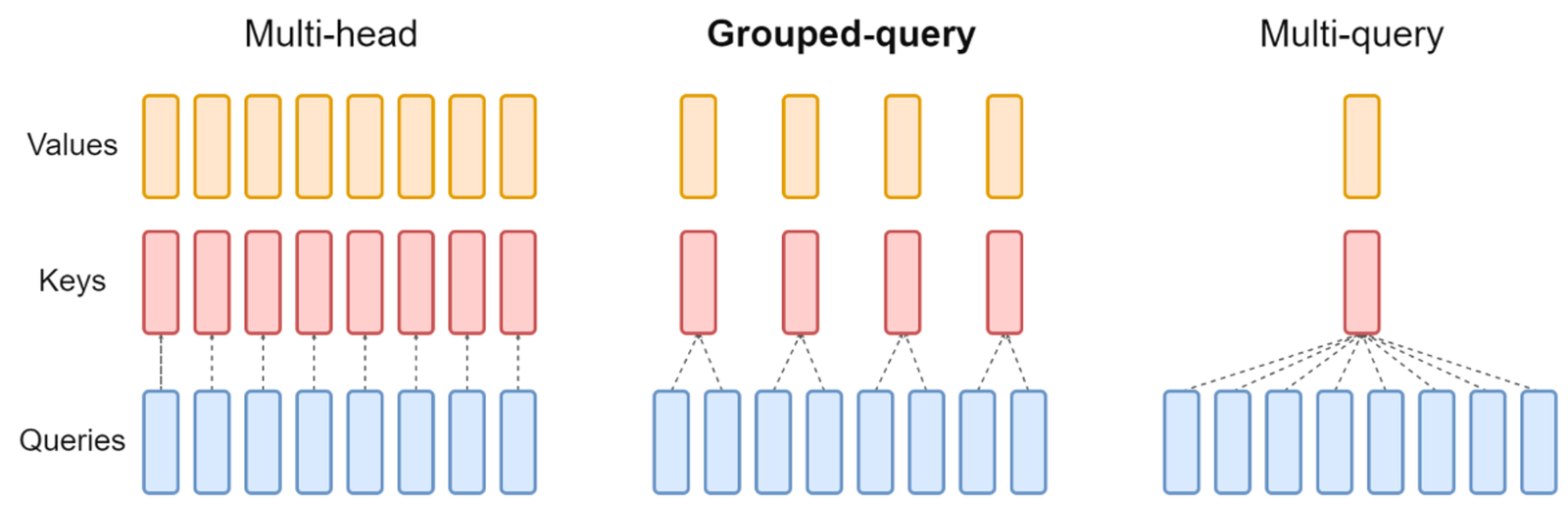
ALiBi 는 Grouped-query 를 사용한다. - as-is: Multi-Head Attention 사용 (K, Q, V 의 개수 = Head 의 개수)
- to-be: ( = ALiBi 방법 )
- Attention Head 들 사이에 weight 를 서로 공유하여 K, V 를 각각 Linear projection 할 때 2개의 Matrix 만을 보유해도 가능하도록 변형한 방식
- Attention Score 연산에 소요되는 시간을 줄일 수 있음
- Input Token n 이 커질수록 더 효과를 보았음
- Conditional computation
- Attention Score 계산 시 중요한 Token 에 대해서만 계산하여 속도를 높이는 방법
- Large RAM GPUs
- 험을 위해 GPU RAM 사이즈를 크게 환경을 구성했음 (뭐… 당연한 얘기)
- 비교 실험을 위해 모델 학습 시 Input Token n 에 따른 성능 비교를 위해서.
- 험을 위해 GPU RAM 사이즈를 크게 환경을 구성했음 (뭐… 당연한 얘기)
방법은 간단한데 안에 숨은 의미는 방대하다.
괜히 세계적인 석학이 아닌가 싶다...
4. 결론
본 논문에서 기존 Transformer 모델에서 가장 큰 약점으로 예측한 부분은 Positional Encoding 였다.
2가지 이유가 있었다.
- input Token n 이 커지면 연산의 복잡도가 올라감
- n 이 커지면 추론 성능이 많이 떨어짐 (성능 및 속도)
- 모델 추론 시 학습 시 설정한 n 보다 큰 N 으로는 추론이 불가능함 (n < N)
2가지 이슈를 해결하기 위한 방법으로 모델의 구조를 변경하였다.
- Positional Embedding 삭제
- Token 들의 위치 정보는 Transformer Layer 안에 Positional Info.(=m) 를 Attention Score 값에 더해주는 방식
- Attention Score 가 Softmax 를 취하기 전에 거리에 따른 페널티 부여
- Token 들의 위치 정보는 Transformer Layer 안에 Positional Info.(=m) 를 Attention Score 값에 더해주는 방식
- Attention Score 연산량 감소
- Multi-Query Attention 사용
- Attention Head 들 사이에 weight 를 서로 공유하여 K, V 를 각각 Linear projection 할 때 2개의 Matrix 만을 보유해도 가능하도록 변형한 방식
- Sparse Attention Score 사용
- window 크기를 지정하여 window 내부에 있는 Token 간의 Attention pattern 만 고려
- Multi-Query Attention 사용
결과적으로 Input token 길이에 따른 PPL 은 4개의 Embedding 방법 중 가장 낮았고 학습 및 추론 속도는 가장 빨랐다.
더불어 VRAM 이 가장 많이 Save 되었다.
이 논문 역시 결론은 뭐니 뭐니 해도 내 방법이 짱이다.! 와 같이 마무리된다.
참고 문헌
- ALiBi 논문 리뷰
- Rotary Position Embedding 설명
마무리,,
그동안 Encoder 모델만 연구해 왔다. Decoder 모델은 이런저런 이유 또는 핑계로 자연스레 멀어졌다.
요즘 같이 Decoder 모델이 흥하는 시기에 이유 또는 핑계는 사라져야 한다.
그래서 보기 시작한 ALiBi 논문이 많이 흥미롭고 왜 GPT 가 그렇게 많은 Max Length 를 처리하는데도 좋은 성능을 보이는지 간접체험한 것 같아 좋았다.
필자의 논문을 통한 연구 F/U 은 22년도부터 멈춰있다.
하나 둘 따라잡아 LLM 전문가로 성장해 나갈 생각이다.
아자아자.!!
'Natural Language Processing > Paper review' 카테고리의 다른 글
| [LoRA] 실무자 맞춤 요점 파악하기 (0) | 2024.02.05 |
|---|---|
| [LoRA] 논문 쉽게 설명하기 (0) | 2024.02.01 |
| [논문 리뷰] Reference and Document Aware Semantic Evaluation Methods for Korean Language Summarization (0) | 2022.11.09 |
| [논문 리뷰] SimCSE: Simple Contrastive Learning of Sentence Embeddings (0) | 2022.08.31 |




댓글