들어가며,,
비즈니스에 해당 논문 기술을 적용한다는 마인드로 논문 리뷰를 하기 때문에 논문 연구 결과 파악을 위한 리뷰와는 다소 차이가 있을 수 있음을 미리 말씀드립니다.
Simple review for parper
Supervised & Unsupervised SimCSE 제안 (21년 4월 발간)

Unsupervised SimCSE (자체적으로 label을 만들어 줌)
- Positive pair: 동일한 문장
- embedding layer에 동일한 문장을 넣어 drop out(p=0.1)을 통해 다른 embedding 값을 얻어줌
- 이러한 drop out 이 최소한의 data augmentation 이라고 함 (다른 방식 ex. 삭제, 대체, etc… 사용해 봤는데 drop out이 성능이 제일 좋았다고 함)
- 어떠한 data augmentation 적용하지 않았을 때(완전 동일한 문장을 pos_pair로 사용)도 좋지 않았다고 함
- Negative pair: 다른 문장
- 같은 mini-batch 내에 있는 다른 문장들을 Negative pair 로 생성 즉, 하나의 pos_pair & 여러 개의(mini-batch - 1 개) neg_pair 가 쌍이 되도록 구성 batch_size 가 더욱 중요한 hyperparameter 가 될 것으로 보임 → Uniformity 향상을 위해
- Training objective (Contrastive learning 방식 사용)
- pos_pair 가까워 지도록, neg_pair 멀어 지도록
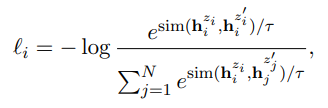
Contrastive learning 방식으로 학습 (Core idea)
- Pos_pair 는 가까워지도록, Neg_par 는 멀어지도록 학습하는 방법
(Alignment & Uniformity 향상시키는 학습 방법)
- 해당 설명은 DBSA SimCSE 발표 자료를 참고 (유튜브 영상으로도 있으니 꼭 보시기를.!)
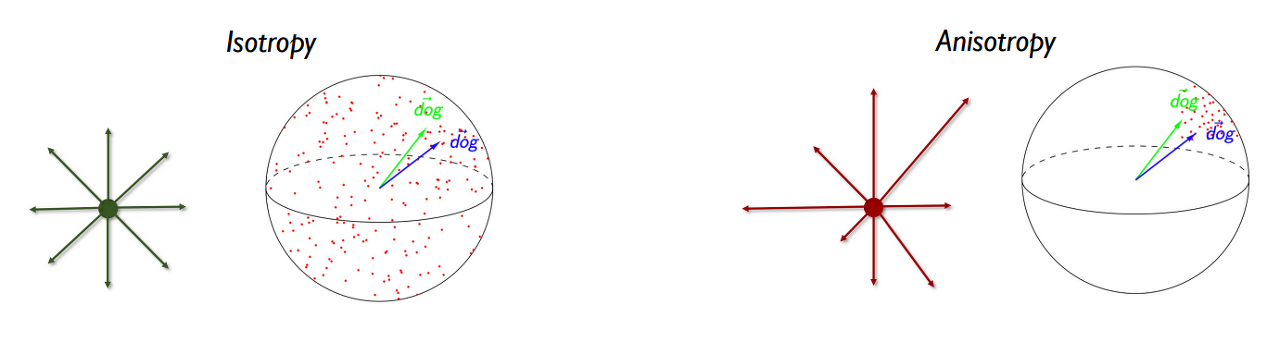
- Alignment : 문맥을 파악하는 능력 (ex. 다른 단어, but 같은 뜻)
- 문맥을 얼만큼 파악할 수 있는지 (paired embedding 가까울수록 좋음)
- Uniformity : 단어 고유의 뜻을 유지하는 능력 (ex. 다른 단어이면 다른 뜻)
- embedding이 얼만큼 균일하게 분포하는지 (균일할수록 좋음)
- Alignment & Uniformity 는 Trade off 관계로 두 가지 수치가 좋아야 좋은 representation(=vector)이라고 할 수 있음
- Alignment가 좋고(작고) Uniformity가 나쁘면(크면) 문맥은 잘 파악하지만 완전히 다른 뜻의 단어도 비슷하다고 판단할 수 있음
- Uniformity가 좋고(작고) Alignment가 나쁘면(작으면) 문맥을 파악하는 능력이 떨어짐
- Alignment & Uniformity 수치와 모델의 성능의 관계
- 단순히 downstream task 에서 SimCSE가 좋았다. 가 아닌 Alignment & Uniformity 분석을 통해 성능 향상 원인을 분석한 점이 재밌었음
- 물론 downstream task에서도 좋은 성능을 기록

Supervised SimCSE
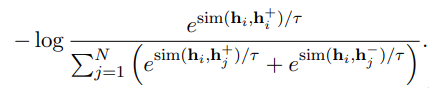
- NLI datasets 사용하여 학습
- Entailment 는 Pos_pair 로, Contradiction 은 hard neg_pair 로 사용 (Triplet 이랑 비슷한 느낌)
마치며,,
가장 흥미로웠던 것은 Alignment & Uniformity 분석을 통해 성능 향상 원인을 분석한 점이다. 타 논문은 보통 Downstream task 에서 sota를 기록했다로 마무리한다면 SimCSE 논문에서는 성능과 두 가지 지표인 Alignment & Uniformity의 상관관계를 연결함으로 성능 향상의 원인을 분석했다. 또한 다양한 실험들(Ablation Studies)을 통해 Hyperparameter setting에 도움을 주기도 했다.
Vector Representation for Sentence 분야의 발전은 초기 백오브워드부터 Sentence BERT까지 다양한 방법으로 연구되어 왔다. 현재는 Contrastive learning을 시작으로(ex. SimCLR) SimCSE를 모티브로 하는 방법이 연구되고 있다. 예시로는 ESimCSE, SNCSE 등이 있다. 관련 연구가 궁금하다면 해당 키워드로 검색하길 바란다. (논문 나온다 ㄷㄷ)
개인적으로 필자가 가장 마음에 들었던 점은 Unsupervised learning으로 Alignment & Uniformity 두 가지 지표가 향상됐다는 사실이다. Pos_pair로 동일한 document를 사용하고 Neg_pair로 mini-batch 내의 다른 document를 사용하기만 해도 성능이 오른다. 이 방식의 연구를 왜 좋다고 하는지 비즈니스 관점에서 서술하고자 한다.
텍스트 데이터를 다루기 어려운 이유는 데이터를 얻기는 쉽지만 정제하기 어렵기 때문이다. 더 큰 에러 사항은 특정 도메인에 특화된 모델을 만들기 위해서는 데이터 어노테이션 작업이 필수이기 때문이다. 많은 시간과 리소스가 필요하기에 텍스트 데이터는 관리하기 어렵다.
본 논문의 기술은 데이터를 정제하고 어노테이션하는 작업을 줄일 수 있다는 장점이 있다. 모델 배포를 위한 모델링을 해본 사람이라면 다들 공감하겠지만 어노테이션 작업이 가장 큰 공수가 든다. 요건 정의부터 시작해서 검수까지... 어후... 지친다. 이렇게 지치는 과정을 단순화 시켜줄 수 있다니 얼마나 좋은가.!! Vector Representation이 필요한 많은 도메인에서 효율적인 사용이 가능할 것이라 믿는다. (필자의 니즈는 SimCSE 내부 실험 및 플젝 적용을 실제로 해보는 거다. 그럼 믿는다인지 필요 없다인지 알 수 있을테니까..)
또한 본 논문의 기술은 일종의 Pretrained embedding model을 만들어주는 방법이 아닐까 생각한다. 기존의 Pretrained BertModel 과 다른 방식으로 학습하지만 Sentence embedding의 관점에서는 Alignment & Uniformity 두 가지를 모두 향상시키기 때문이다. (기존의 Pretrained BertModel은 Alignment는 좋지만 Uniformity가 좋지 않다.) Pretrain 만으로 좋은 성능을 보이는 모델을 만들 수 있기 때문에 장점이라 생각한다. (일종의 zero shot learning이지 않을까?)
기존 대비 성능이 얼마나 좋아졌는지, 수치는 어느 정도인지 궁금하다면 해당 논문을 직접 꼼꼼히 보기를 권장한다.
'Natural Language Processing > Paper review' 카테고리의 다른 글
| [LoRA] 실무자 맞춤 요점 파악하기 (0) | 2024.02.05 |
|---|---|
| [LoRA] 논문 쉽게 설명하기 (0) | 2024.02.01 |
| [ALiBi] Train Short, Test Long: Attention With Linear Biases Enables Input Length Extrapolation (0) | 2024.01.17 |
| [논문 리뷰] Reference and Document Aware Semantic Evaluation Methods for Korean Language Summarization (0) | 2022.11.09 |




댓글