Total loss 정의
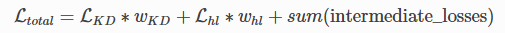
- KD loss : Knowledge Distillation loss로 학생 모델의 logits이 교사 모델의 logits 분포를 따라가도록 학습
- HL loss : Hard Label로 학생 모델의 logits이 groud truth of label을 따라가도록 학습
- Intermediate_losses : 학생 모델의 encoder layer 분포가 교사 모델의 encoder layer 분포를 따라가도록 학습
다양한 기능 제공 > 자세한 사항은 textbrewer docs 참고
- KD loss 관련 기능
- KD loss weight 설정
- temperature 관련 Parameters
- loss type 관련 Parameters
- HL loss 관련 기능 (+ Inermediate_loss 관련 기능)
- intermediate_matches 설정 필요
- weight
- loss type
- feature : ['attendtion', 'hidden']
- proj
- intermediate_matches 설정 필요
학습 방법
💡 총 5가지 학습 방법 제시
- BasicDistiller : 하나의 교사 모델 사용한 경량화 학습 class (intermediate_matches 지원 x)
- GeneralDistiller : intermediate_matches 사용한 경량화 학습 class (하나의 교사 모델 추천)
- MultiTeacherDistiller : 여러 개의 교사 모델을 사용한 경량화 학습 class (intermediate_matches 지원 x)
- MultiTaskDistiller : 여러 개의 task 추론 가능한 하나의 학생 모델을 학습하는 class
- BasicTrainer : 단순한 fine-tune 학습 class
Beeny's recommend: GeneralDistiller class
GeneralDistiller 학습 과정
# train_cofig 정의
from textbrewer import TrainingConfig
train_config = TrainingConfig(device = device,
log_dir = output_dir,
output_dir = output_dir)
# distill_config 정의
from textbrewer import DistillationConfig
distill_config = DistillationConfig(temperature = 8,
intermediate_matches = [{'layer_T':10,
'layer_S':3,
'feature':'hidden',
'loss': 'hidden_mse',
'weight' : 1}])
# model_T & model_S 정의: huggingface transformers BertModel class 사용
# adaptor_T & adaptor_S 정의
def adaptor_T(batch, model_output):
return {"logits" : (model_output[1],),
'logits_mask' : (batch['attention_mask'],),
'hidden' : (model_output[2],)}
def adaptor_S(batch, model_output):
return {"logits" : (model_output[1],),
'logits_mask' : (batch['attention_mask'],),
'hidden' : (model_output[2],)}
# 학습 진행 → 객체 생성, train 메서드 함수로 학습
from textbrewer import GeneralDistiller
distiller = GeneralDistiller(train_config,
distill_config,
model_T,
model_S,
adaptor_T,
adaptor_S)
distiller.train(optimizer,
train_dataloader,
num_train_epochs,
scheduler_class,
scheduler_args,
max_grad_norm = 1.0, # default 값이 -1.0 이기 때문에 수정 필요
callback = callback)- 여기서 optimizer, scheduler는 HuggingFace transformers에서 가져와 사용하는 걸 추천한다.
- 물론 주의할 점이 있다. 주의 사항은 다음 글에서 소개하려 한다.
TextBrewer 패키지 관련 글
이전 글
2022.06.17 - [Natural Language Processing/Model Compression] - [경량화 패키지] TextBrewer란?
2022.06.17 - [Natural Language Processing/Model Compression] - [경량화 패키지] TextBrewer scripts info.
이후 글
2022.06.17 - [Natural Language Processing/Model Compression] - [경량화 패키지] TextBrewer 사용 후기
반응형
'Natural Language Processing > Model Compression' 카테고리의 다른 글
| [논문 리뷰] Distilling Linguistic Context for Language Model Compression (0) | 2022.06.23 |
|---|---|
| [경량화 패키지] TextBrewer 사용 후기 (0) | 2022.06.17 |
| [경량화 패키지] TextBrewer scripts info. (0) | 2022.06.17 |
| [경량화 패키지] TextBrewer란? (0) | 2022.06.17 |




댓글