목적
💡 기존의 경량화는 단어 간 관계를 고려하지 않았고 단어가 model의 encoder layer를 통과하며 어떻게 변화하는지도 고려하지 않았음
- 기존 경량화: 단순히 학생 모델이 선생 모델의 weight를 따라가도록, logit 값을 따라가도록 학습
- 본 논문: logit 값을 따라갈 뿐만 아니라 단어 간 관계 및 단어가 encoder layer를 통과하며 어떻게 변하는지도 고려해서 학습
실험 방법
- Model: Google’s Multi-lingual-BERT model
- Pre-train BERT 모델에 Distillation하여 경량화 된 BERT모델을 만들고 각 task datasets을 이용한 Fine-tuning 후 성능 비교
- Pre-train distillation datasets: English Wiki

- Pre-train BERT 모델을 각 task datasets을 이용하여 Fine-tuning한 뒤 각 task datasets을 이용하여 Distillation 학습 진행 후 성능 비교
- Fine-tuning distillation datasets: each tasks datasets

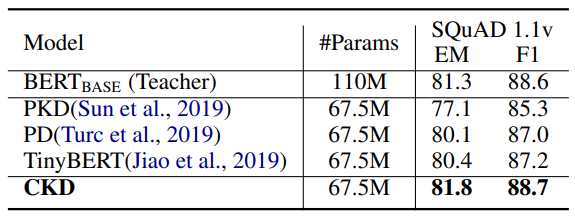
당연히(?) 대부분의 task에서 다른 경량화 모델에 비해 좋은 성능을 보였다고 함
- 나름(?) 유의미한 성능 차이를 보이는 task는 CoLA, SQuAD 1.1v
- task desc.
- CoLA (Corpus of Linguistic Acceptability) : 문장이 문법적으로 정확한지에 대한 Task
- SQuAD 1.1v : 질의응답(Question & Answer) Task
- 그 외에는 큰 차이 없어 보임.. (내(빈) 생각에 CLS, MLBL, NER에는 큰 변화가 없을 것 같음. ESUM은 성능이 살짝 더 좋을 것 같은데... 큰 차이는 없을 것이라 생각)
- task desc.
학습 방법
Loss_1: 단어와 단어 사이의 관계(pair-wise words relation) & 3개의 단어 사이의 관계(triple-wise words relation) 고려
Loss_2: 각 단어가 model의 encoder layer를 통과하며 어떻게 변화하는지 고려
Loss_3: 기존의 경량화 방법론처럼 logit 값을 따라가도록 학습

- Word Relation
- 2개의 단어 사이의 관계를 loss_a로 사용
- 3개의 단어 사이의 관계를 loss_b로 사용
- Loss_1 = w_aloss_a + w_bloss_b
- Layer Transforming Relation
- 단어가 각 layer를 통과하며 어떻게 변화하는지 고려
- teacher model의 변화를 student model의 변화가 따라가도록 학습
- Word Relation처럼 단어 representation이 2번 변할때(pair-wise), 3번 변할때(triple-wise) 변화량을 loss로 사용
- ex. input sent: [나는, 이원빈, 입니다]
- 나는 = [layer_1_나는, layer_2_나는, ... , layer_n_나는]
- 이원빈 = [layer_1_이원빈, layer_2_이원빈, ... , layer_n_이원빈]
- 입니다 = [layer_1_입니다, layer_2_입니다, ... , layer_n_입니다]
Total Loss
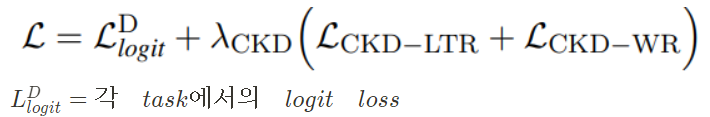
- pretrain: mlm logit loss
- finetune: each task logit loss
논문 실험 및 결과 비교
이 논문에서도 student model 학습을 위해 teacher model의 어떤 encoder layer를 선택할지 고민했다고 함. 고민의 근거는 DistilBERT(2019)를 참고.
그 외에 param. 수 비교, 계산량(flops) 비교, abulation studies 등등 여러 실험을 했고, outputs를 비교 했다고 함
해당 논문은 흥미로운 경량화 방법이지만 개인적으로 학습 시간이 너무 오래 걸리고 resource가 많이 필요할 것 같아 우려된다. 학습하는 환경 및 학습하는데 걸린 시간을 논문에 추가했으면 좋지 않았을까 생각한다.
반응형
'Natural Language Processing > Model Compression' 카테고리의 다른 글
| [경량화 패키지] TextBrewer 사용 후기 (0) | 2022.06.17 |
|---|---|
| [경량화 패키지] TextBrewer 학습 Process (0) | 2022.06.17 |
| [경량화 패키지] TextBrewer scripts info. (0) | 2022.06.17 |
| [경량화 패키지] TextBrewer란? (0) | 2022.06.17 |




댓글