LLM 오픈소스 중 가장 유명한 LLaMA-Factory 를 파악하고 있다.
그 중 SFT 학습 시 Tokenizer padding_side 를 어떻게 설정하는지 확인했다.
본 포스팅은 오픈소스인 LLaMA-Factory 에서 SFT 학습 시 Tokenizer padding_side 셋팅이 어떻게 되어 있는지 코드를 통해 확인한 결과를 소개한다.
목차
1. 실무자는 바쁘다.! 결론부터 말씀드릴게요.
2. padding_side = 'right' 에 의한 데이터 구성
3. padding_side = 'left' 에 의한 데이터 구성
4. 필자 리뷰

1. 실무자는 바쁘다.! 결론부터 말씀드릴게요.
필자가 파악하고자 한 주요 원인은 다음과 같다.
LLaMA-Factory 로 내가 원하는 데이터 형태로 학습해주려면 어느 정도 커스터마이징 해야할까?
padding_side 를 left & right 로 각각 셋팅하여 SFT 학습 및 검증해봤을 때는 left 일 때 성능이 더 좋았다.
그런데 문제는... 왜 그런지 솔직히 잘 모르겠다. (이것도 Hyper-Parm. 이다보니..)
많은 모델의 config 를 보면 padding side 가 right 로 셋팅되어 있었기 때문에 left 가 정답이라 말하기도 어려운 것 같다.
성능 향상을 목표로 다양한 실험을 하기 위해 LLaMA-Factory 에서는 Tokenizer padding_side 가 기본적으로 어떻게 셋팅되어 있는지 확인했다.
- AutoTokenizer 로 Tokenizer 를 불러올 때 padding_side 가 'right' 로 고정되어 있다.
- src/llamafactory/model/loader.py 에서 load_tokenizer 함수를 보면 알 수 있다.
즉, LLaMA-Factory 에서는 padding_side 를 'left' 로 학습 및 검증하고자 한다면 코드를 일부 수정해줘야 한다.
그렇다면 구체적으로 padding_side 에 의해 데이터가 어떻게 구성되는지 예시와 함께 확인해보자.
2. padding_side = 'right' 에 의한 데이터 구성
LLaMA-Factory 에서는 Tokenizer load 시 기본적으로 padding_side = 'rigth' 로 기본 셋팅되어 있다.
즉, tokenizer_config.json 에 padding_side = 'left' 로 되어 있어도 Tokenizer load 시 right 로 무조건 변경된다는 뜻이다.
src/llamafactory/model/loader.py 에서 load_tokenizer 함수를 보면 알 수 있다.
load_tokenizer 함수를 보며 확인해보자.
def load_tokenizer(model_args: "ModelArguments") -> "TokenizerModule":
r"""
Loads pretrained tokenizer and optionally loads processor.
Note: including inplace operation of model_args.
"""
init_kwargs = _get_init_kwargs(model_args)
config = load_config(model_args)
try:
tokenizer = AutoTokenizer.from_pretrained(
model_args.model_name_or_path,
use_fast=model_args.use_fast_tokenizer,
split_special_tokens=model_args.split_special_tokens,
padding_side="right", # load 시 항상 right 로 불러온다는 걸 알 수 있다.
**init_kwargs,
)
except ValueError: # try the fast one
tokenizer = AutoTokenizer.from_pretrained(
model_args.model_name_or_path,
use_fast=True,
padding_side="right", # load 시 항상 right 로 불러온다는 걸 알 수 있다.
**init_kwargs,
)그렇다면 padding_side = "right" 일 때 데이터의 구성 즉, input_ids 는 어떻게 구성되는지 예시와 함께 알아보자.
아래 더보기를 클릭해보면 보면 초반에 Text 가 쭉 나오다가 <|end_of_text|> 가 반복됨을 알 수 있다.
이는 right padding 의 영향으로 {# of token < max_length} 이면 {max_length - # of token} 만큼 오른쪽 맨 끝에 PAD token 으로 채우기 때문이다.
본 예시에서는 PAD token 이 <|end_of_text|> 이다.
<|begin_of_text|><|start_header_id|>user<|end_header_id|>
Imagine a future world where robots and humans coexist. Describe it.<|eot_id|><|start_header_id|>assistant<|end_header_id|>
In this future world, robots and humans coexist in harmony, with robots serving as intelligent assistants and helpers to humans. They work alongside each other in various industries, from manufacturing, to healthcare and hospitality. In daily life, you can see robots performing tasks such as cleaning, cooking, and running errands. They have become an integral part of modern society, making everyday life easier and more efficient.
In this world, robots are equipped with sophisticated artificial intelligence, allowing them to think, learn, and adapt in ways similar to humans. They have become more advanced than ever, with the ability to communicate and interact with humans, understand social norms, and even express emotions. Some high-end robots are virtually indistinguishable from humans.
One of the most significant benefits of the coexistence of humans and robots is the increased productivity and efficiency that it brings. Tasks that were previously time-consuming or hazardous can now be completed with ease, and complex problems can be solved more quickly with the combined brainpower of humans and robots. In healthcare, for example, robots can assist with surgeries, provide care for the elderly, and monitor patients' health.
This future world has its challenges as well, such as the integration of robots into society and the potential for widespread job automation. However, with careful planning and foresight, humanity has embraced the coexistence with robots and worked to ensure that it is a positive and mutually beneficial relationship.
In summary, this future world where robots and humans coexist is one of technological progress, increased efficiency, and a new era of collaboration between man and machine.<|eot_id|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|>
- PAD token 은 연산 시 모델에 아무 영향을 주지 않는 효과를 주기 위해 사용하는 special token 이다.
그렇다면 padding_side 가 left 일 때는 어떻게 생겼을까??
3. padding_side = 'left' 에 의한 데이터 구성
padding_side 를 left 로 셋팅하기 위해서는 LLaMA-Factory 에서 src/llamafactory/model/loader.py 에서 load_tokenizer 함수를 수정해야 한다. 2가지 방법이 있다.
- Tokenizer 를 load 할 때 padding_side 를 'left' 로 수정해준다.
- Tokenizer load 시 padding_side arg. 를 삭제하고, tokenizer_config.json 에 padding_side = 'left' 로 셋팅해준다.
- 아래처럼 해주면 padding_side 가 left 가 된다.
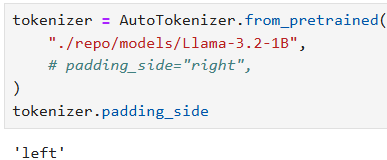

그렇다면 padding_side = "left" 일 때 데이터의 구성 즉, input_ids 는 어떻게 구성되는지 예시와 함께 알아보자.
아래 더보기를 클릭해보면 보면 초반에 <|end_of_text|> 가 반복되다가 Text 가 나오는 걸 알 수 있다.
이는 left padding 의 영향으로 {# of token < max_length} 이면 {max_length - # of token} 만큼 왼쪽 맨 끝부터 PAD token 으로 채우기 때문이다.
본 예시에서는 PAD token 이 <|end_of_text|> 이다.
<|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|end_of_text|><|begin_of_text|><|start_header_id|>user<|end_header_id|>
Imagine a future world where robots and humans coexist. Describe it.<|eot_id|><|start_header_id|>assistant<|end_header_id|>
In this future world, robots and humans coexist in harmony, with robots serving as intelligent assistants and helpers to humans. They work alongside each other in various industries, from manufacturing, to healthcare and hospitality. In daily life, you can see robots performing tasks such as cleaning, cooking, and running errands. They have become an integral part of modern society, making everyday life easier and more efficient.
In this world, robots are equipped with sophisticated artificial intelligence, allowing them to think, learn, and adapt in ways similar to humans. They have become more advanced than ever, with the ability to communicate and interact with humans, understand social norms, and even express emotions. Some high-end robots are virtually indistinguishable from humans.
One of the most significant benefits of the coexistence of humans and robots is the increased productivity and efficiency that it brings. Tasks that were previously time-consuming or hazardous can now be completed with ease, and complex problems can be solved more quickly with the combined brainpower of humans and robots. In healthcare, for example, robots can assist with surgeries, provide care for the elderly, and monitor patients' health.
This future world has its challenges as well, such as the integration of robots into society and the potential for widespread job automation. However, with careful planning and foresight, humanity has embraced the coexistence with robots and worked to ensure that it is a positive and mutually beneficial relationship.
In summary, this future world where robots and humans coexist is one of technological progress, increased efficiency, and a new era of collaboration between man and machine.<|eot_id|>
지금까지 padding_side 가 right 일 때, left 일 때 각각 확인했다.
추가적으로 하나만 더 확인해보았다.
sLLM 에서 PAD token 은 없는 경우가 많다.
실제로 필자가 테스트한 Llama-3.2-1B 모델에도 PAD token 이 없다.
그런데 어떻게 생겼을까? (간단하게만 소개하겠다.)
- src/llamafactory/data/template.py 에서 Template class 에서 PAD token 을 생성해준다.
- fix_special_tokens method 를 통해 생성
- PAD token 이 없으면 eos_token 을 pad_token 으로 지정
- tokenizer.pad_token = tokenizer.eos_token
- 모델은 패딩 된 부분을 실제 문장의 끝으로 간주하고 무시하기 때문에 eos_token 을 pad_token 으로 사용
- 이는 곧 모델이 학습할 때 패딩된 부분에 주의를 기울이지 않고, 실제 문장에 집중하여 학습할 수 있도록 도와주는 효과를 줌
- 만약 EOS token 이 없으면 강제로 만들어줌
- self._add_or_replace_eos_token(tokenizer, eos_token="<|endoftext|>")
4. 필자 리뷰
LLaMA-Factory 코드는 진짜 상당히 잘 짜여져 있다.
코드 구조도 가독성 좋게 구분되어 있어서 커스터마이징 하기도 좋다.
앞으로 LLaMA-Factory 에 대해 몇 가지만 더 확인하려한다.
- max_length 셋팅을 어떻게 하는가?
- README.md 에 있는 예시로 테스트해보니 max_length 가 자동으로 셋팅되더라.
- Full Parameter tuning 은 어떻게 하는가? (LoRA 같은거 안 쓰고)
- README.md 에 있는 예시로만 테스트해봐서 full tuning 은 안 해봤다.
- 해당 코드가 어딨는지 정도만 확인하려한다.
- 원하는 Accelerate 사용을 어떻게 하는가?
- FSDP 로 학습하고 싶은데 FSDP 사용을 위해 model 을 감싸주는게 어딨는지 모르겠다...
해당 사항을 파악하게 되면 포스팅하도록 하겠다.
마무리,,
정말 유명하고 많이들 사용한 LLaMA-Factory 를 이제야 확인한게 다소 늦은감이 없잖아 있다.
그리고 요즘엔 LLM 의 연구 방향이 강화학습 쪽으로 확정된 것 같은데 유행에 뒤쳐지고 있다는 생각도 한다.
마치 DeepSeek 처럼 말이다... (강화학습의 효용이 확실하게 증명된 것 같다. 더 강화학습 공부해야 되는데...)
EduTech 산업으로 와서 NLP 관련 연구 F/U 이 늦어지는건 당연하긴 하지만 아쉬운 점도 많다.
나는 출발점도 현재 정체성도 NLP 연구원이라고 생각하기 때문이다.
어느 산업에 있든 LLM 은 선택이 아닌 필수가 되어가고 있다.
부지런히 F/U 하여 NLP 연구원으로서 정체성을 지키려한다.
'Python > 패키지 훓어보기' 카테고리의 다른 글
| [PyTorch] nn.Transformer 모델 구조 상세 확인 (0) | 2025.03.12 |
|---|---|
| [LLaMA-Factory] LoRA Adapter 확인 (0) | 2025.02.27 |
| [LLaMA-Factory] PT&SFT 학습 데이터는 어떻게 만들어지는가? (1) | 2025.01.22 |



댓글