LLM 오픈소스 중 가장 유명한 LLaMA-Factory 를 파악하고 있다.
그중 Pretrain(a.k.a PT) 과 Supervised Fine-Tuning(a.k.a SFT) 에서 학습 데이터를 어떤 형태로 만드는지 실무자로서 가장 궁금했다.
추후에 회사 프로젝트에서 sLLM 을 학습해야 한다면 LLaMA-Factory 도 좋은 수단으로 생각했기 때문에 데이터는 어떤 형태로 구성되는지 소스 코드를 통해 상세하게 파악할 필요가 있었기 때문이다.
본 포스팅은 오픈소스인 LLaMA-Factory 에서 PT, SFT 학습 시 학습 데이터를 어떻게 encode 하는지 그 과정과 결과를 소개한다.
목차
1. 실무자는 바쁘다.! 결론부터 말씀드릴게요.
2. PT 학습 시 학습 데이터 형태
3. SFT 학습 시 학습 데이터 형태
4. 필자 리뷰

1. 실무자는 바쁘다.! 결론부터 말씀드릴게요.
필자가 파악하고자 한 주요 원인은 다음과 같다.
LLaMA-Factory 로 내가 원하는 데이터 형태로 학습해주려면 어느 정도 커스터마이징 해야할까?
필자는 sLLM 으로 DAPT 및 TAPT 목적으로 Continual-Pretrain 도 해봤고, 프로젝트 적용을 위해 SFT 및 DPO 학습도 해봤기 때문에 가장 궁금했던 점이 LLaMA-Factory 에서 제공하는 학습 데이터의 형태였다.
결론은 다음과 같다.
- Continual_pretrain 을 위해 학습 데이터 구성을 아래 논문과 같은 형태로 신경써준다면 오픈소스 커스터마이징이 필요하다.
- SFT 를 위해 학습 데이터 구성은 chat_template 에 의해 검토가 반드시 필요하다.
- 상세한 내용을 보고 싶다면 `3. SFT 학습 시 학습 데이터 형태` 로 이동하세요.
자, 먼저 PT 학습 시 학습 데이터의 형태가 어떻게 구성되어 있는지 예시와 함께 확인해보자.
2. PT 학습 시 학습 데이터 형태
독자들이 실습하며 직접 확인해볼 수 있도록 실습용 코드와 파악한 LLaMA-Factory python script 파일을 소개하며 진행하겠다.
먼저 LLaMA-Factory github 에 가면 사용법이 있다. 필자는 그 중 아래와 같은 코드를 통해 lora 로 Pretrain 을 진행했다.
#!/bin/bash
llamafactory-cli train examples/train_lora/llama3_lora_pretrain.yaml- 모델은 huggingface hub 에서 meta llama-3.2-1B 을 사용했다.
- 검토가 목적이었기에 작은 size 의 모델로 진행
- 학습 데이터는 LLaMA-Factory 에서 예시로 제공한 c4_demo 를 사용했다.
- 리소스를 최소화 시키기 위해 train_batch_size 와 gradient_accumulation_steps 모두 1로 설정했다.
- cutoff_len 은 1024 로 설정했다.
PT 학습의 경우, 학습 및 데이터 전처리는 아래와 같은 경로의 python script 가 활용된다.
- 학습 시: LLaMA-Factory/src/llamafactory/train/pt
- trainer.py : huggingface Trainer class 를 상속받아 일부 메서드를 수정한 CustomTrainer 사용
- workflow.py : run_pt 함수를 통해 Model, Tokenizer, Data 를 load 한 뒤 CustomTrainer 를 통해 모델 학습 및 저장
- 데이터 전처리 시: LLaMA-Factory/src/llamafactory/data/processors
- pretrain.py : Data 를 Tokenizer 하여 학습 및 검증용 데이터로 전처리
이 중 함께 확인해볼 코드는 pretrain.py 이다.
코드는 아래와 같이 구성되어 있다. (출처: LLaMA-Factory github)
def preprocess_pretrain_dataset(
examples: Dict[str, List[Any]], tokenizer: "PreTrainedTokenizer", data_args: "DataArguments"
) -> Dict[str, List[Any]]:
# build grouped texts with format `X1 X2 X3 ...` if packing is enabled
eos_token = "<|end_of_text|>" if data_args.template == "llama3" else tokenizer.eos_token
text_examples = [messages[0]["content"] + eos_token for messages in examples["_prompt"]]
if not data_args.packing:
if data_args.template == "gemma":
text_examples = [tokenizer.bos_token + example for example in text_examples]
result = tokenizer(text_examples, add_special_tokens=False, truncation=True, max_length=data_args.cutoff_len)
else:
tokenized_examples = tokenizer(text_examples, add_special_tokens=False)
concatenated_examples = {k: list(chain(*tokenized_examples[k])) for k in tokenized_examples.keys()}
total_length = len(concatenated_examples[list(concatenated_examples.keys())[0]])
block_size = data_args.cutoff_len
total_length = (total_length // block_size) * block_size
result = {
k: [t[i : i + block_size] for i in range(0, total_length, block_size)]
for k, t in concatenated_examples.items()
}
if data_args.template == "gemma":
for i in range(len(result["input_ids"])):
result["input_ids"][i][0] = tokenizer.bos_token_id
return result코드에서 text_examples 를 통해 데이터가 어떻게 구성되는지 알 수 있다.
content 마다 마지막에 eos_token 을 추가하여 list 에 append 시켜주는 형태다.
또한 data_args.packing 설정을 통해 content 를 packing 할건지 그렇지 않을건지 선택할 수 있다.
- data_args.packing == True 인 경우
- 데이터 구성: {content-1} [eos_token]
- data_args.packing == False 인 경우
- 데이터 구성: {content-1} [eos_token] {content-2} [eos_token] ... {content-n} [eos_token]
- 이 설정을 사용한다면 max_seq_length 인 data_args.cutoff_len 에 따라 지정된 길이만큼 잘라준다.
마지막으로 data_args.template 에 따라 데이터 별 맨 앞에 [bos_token] 을 추가할지 여부를 선택할 수 있다.
이번엔 c4_demo 데이터 예시와 함께 위 코드를 직접 살펴보자.
c4_demo 는 아래와 같이 json format 으로 되어 있다.

이해를 돕기 위해 text 로 출력했다.
Don’t think you need all the bells and whistles? No problem. McKinley ~~
If you want ~~ addressed.<|end_of_text|>To the apparent surprise of everyone, ~~~
As you might ~~
Our partnership ~~ for years to come.<|end_of_text|>I hadn’t been to Red Mountain in over 4 years ~~~
~~ at Red Mountain. Of course staying in one
위 접은글을 펼쳐보면 json 파일 기준 첫 번째 index 인 text 가 쭉 나오고 그 뒤에 [eos_token] 인 <|end_of_text|> 가 나온다. 그리고 <|end_of_text|> 가 한번 더 나온다. 이는 3개의 text 가 max_length_seq 인 1024 내에 모두 병합되었음을 뜻한다.
input_ids 는 아래와 같다. (너무 길어서 간략하게 축소되었다.)
(Pdb) dataset.to_pandas()['input_ids'][0]
array([ 8161, 1431, 1781, ..., 19994, 304, 832], dtype=int32)
(Pdb) dataset.to_pandas()['input_ids'][0].shape
(1024,)
이러한 이유가 바로 필자가 말한 결론인 `Continual_pretrain 을 위해 학습 데이터 구성을 In-Context Pretraining 논문과 같은 형태로 신경써준다면 커스터마이징이 필요하다`고 한 이유다.
커스터마이징이 필요하다면 아래 python script 를 수정하면 된다.
- LLaMA-Factory/src/llamafactory/data/processors/pretrain.py
3. SFT 학습 시 학습 데이터 형태
독자들이 실습하며 직접 확인해볼 수 있도록 실습용 코드와 파악한 LLaMA-Factory python script 파일을 소개하며 진행하겠다.
먼저 LLaMA-Factory github 에 가면 사용법이 있다. 필자는 그 중 아래와 같은 코드를 통해 qlora 로 SFT 진행했다.
#!/bin/bash
llamafactory-cli train examples/train_qlora/llama3_lora_sft_awq.yaml- 모델은 huggingface hub 에서 LGAI-EXAONE/EXAONE-3.5-2.4B-Instruct 를 사용했다.
- 왜 SFT 를 위해서는 커스터마이징이 필요한지 예시를 통해 보여주기 위
- 학습 데이터는 LLaMA-Factory 에서 예시로 제공한 identity 를 사용했다.
- 리소스를 최소화 시키기 위해 train_batch_size 와 gradient_accumulation_steps 모두 1로 설정했다.
- cutoff_len 은 1024 로 설정했다.
SFT 학습의 경우, 학습 및 데이터 전처리는 아래와 같은 경로의 python script 가 활용된다.
- 학습 시: LLaMA-Factory/src/llamafactory/train/sft
- trainer.py : huggingface Seq2SeqTrainer class 를 상속받아 일부 메서드를 수정한 CustomSeq2SeqTrainer 사용
- workflow.py : run_sft 함수를 통해 Model, Tokenizer, Template, Data 를 load 한 뒤 CustomSeq2SeqTrainer 를 통해 모델 학습 및 저장
- 데이터 전처리 시: LLaMA-Factory/src/llamafactory/data
- template.py: model tokenizer_config.json 에 chat_template 을 불러온 뒤 상황에 따라 template 을 수정
- preprocess.py: sft 학습 시 packing 여부에 따른 데이터 전처리 함수 선택
- processors/supervised.py : Data 를 Tokenizer 하여 학습 및 검증용 데이터로 전처리
이 중 함께 확인해볼 코드는 processors/supervised.py 이다.
코드는 아래와 같이 구성되어 있다. (출처: LLaMA-Factory github)
def _encode_supervised_example(
prompt: Sequence[Dict[str, str]],
response: Sequence[Dict[str, str]],
system: Optional[str],
tools: Optional[str],
images: Sequence["ImageInput"],
videos: Sequence["VideoInput"],
template: "Template",
tokenizer: "PreTrainedTokenizer",
processor: Optional["ProcessorMixin"],
cutoff_len: int,
train_on_prompt: bool,
mask_history: bool,
) -> Tuple[List[int], List[int]]:
messages = template.mm_plugin.process_messages(prompt + response, images, videos, processor)
input_ids, labels = template.mm_plugin.process_token_ids([], [], images, videos, tokenizer, processor)
encoded_pairs = template.encode_multiturn(tokenizer, messages, system, tools)
total_length = len(input_ids) + (1 if template.efficient_eos else 0)
if mask_history:
encoded_pairs = encoded_pairs[::-1] # high priority for last turns
for turn_idx, (source_ids, target_ids) in enumerate(encoded_pairs):
if total_length >= cutoff_len:
break
source_len, target_len = infer_seqlen(len(source_ids), len(target_ids), cutoff_len - total_length)
source_ids = source_ids[:source_len]
target_ids = target_ids[:target_len]
total_length += source_len + target_len
if train_on_prompt:
source_label = source_ids
elif template.efficient_eos:
source_label = [tokenizer.eos_token_id] + [IGNORE_INDEX] * (source_len - 1)
else:
source_label = [IGNORE_INDEX] * source_len
if mask_history and turn_idx != 0: # train on the last turn only
target_label = [IGNORE_INDEX] * target_len
else:
target_label = target_ids
if mask_history: # reversed sequences
input_ids = source_ids + target_ids + input_ids
labels = source_label + target_label + labels
else:
input_ids += source_ids + target_ids
labels += source_label + target_label
if template.efficient_eos:
input_ids += [tokenizer.eos_token_id]
labels += [tokenizer.eos_token_id]
return input_ids, labels코드에서 input_ids 를 통해 데이터가 어떻게 구성되는지 알 수 있다.
IGNORE_INDEX 는 LLaMA-Factory/src/llamafactory/extras/constants.py 에 있는데 -100 으로 고정되어 있다.
코드 확인해서 형태 분석하는데 시간이 부족한 실무자를 위해 준비했다. 예시 !!
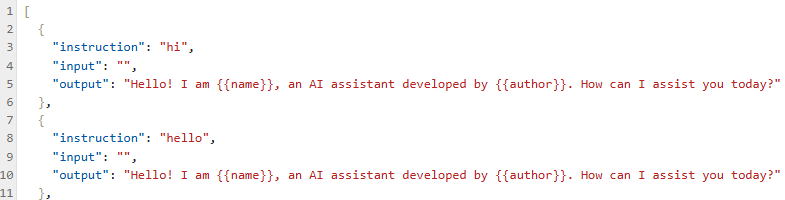
이해를 돕기 위해 text 로 출력했다.
[BOS]<|start_header_id|>user<|end_header_id|>
hi<|eot_id|><|start_header_id|>assistant<|end_header_id|>
Hello! I am {{name}}, an AI assistant developed by {{author}}. How can I assist you today?[|endofturn|]
앞서 사용한 모델은 `LGAI-EXAONE/EXAONE-3.5-2.4B-Instruct` 라 했다. 이상하지 않은가?
뭐가 이상하냐?? 사용되는 special token 의 구성이 tokenizer_config.json 에 있는 chat_template 과 좀 다르다.!!
어떻게 다른지 예시를 통해 살펴보자.
`LGAI-EXAONE/EXAONE-3.5-2.4B-Instruct` 모델의 chat_template 을 활용하면 다음과 같다.
# Choose your prompt
user_prompt = "hi" # Korean example
assistant_prompt = "Hello! I am {{name}}, an AI assistant developed by {{author}}. How can I assist you today?"
messages = [
{"role": "system",
"content": "You are EXAONE model from LG AI Research, a helpful assistant."},
{"role": "user", "content": user_prompt},
{"role": "assistant", "content": assistant_prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False
# add_generation_prompt=True,
# return_tensors="pt"
)
print(text)위와 같이 text 를 chat_template 으로 출력해보면 아래와 같은 text 가 나온다.
[|system|]You are EXAONE model from LG AI Research, a helpful assistant.[|endofturn|] [|user|]hi [|assistant|]Hello! I am {{name}}, an AI assistant developed by {{author}}. How can I assist you today?[|endofturn|]
이러한 차이가 발생하는 이유는 LLaMA-Factory/src/llamafactory/data/template.py 에서 chat_template 을 일부 수정해주기 때문이다.
이러한 이유가 바로 필자가 말한 결론인 `SFT 를 위해 학습 데이터 구성은 chat_template 에 의해 검토가 반드시 필요하다`고 한 이유다.
커스터마이징이 필요하다면 아래 python script 를 수정하면 된다.
- LLaMA-Factory/src/llamafactory/data/template.py
- LLaMA-Factory/src/llamafactory/data/processors/supervised.py
4. 필자 리뷰
LLaMA-Factory 코드는 진짜 상당히 잘 짜여져 있다.
github README.md 만 보고도 쉽게 학습 코드를 돌려볼 수 있고 코드 구조화가 잘 되어 있어 파악하기도 용이하다.
이렇게 잘 짜여진 코드를 보고 있자면 괜히 기분이 좋아진다. (약간 변태 스럽기도 하다🤣)
필자는 이렇게 생각한다.
결국 모델의 성능은 내가 하고자 하는 바를 명확히 이해하고, 이를 모델에 적용하여야 사전에 설계한 결과를 얻어낼 확률이 높아진다.
때문에 실무자들에게 LLaMA-Factory 의 커스터마이징은 선택이 아닌 필수다.
하여 필자는 추가적으로 LLaMA-Factory 의 더욱 세부적인 부분을 추가로 분석할 예정이다.
이러한 분석의 최종 목표는 적은 리소스 환경(ex. disk, vram 등)에서도 모델의 성능을 높이기 위해 LLaMA-Factory 를 커스터마이징하여 모델 학습 및 성능 검증을 진행하는 것이다.
추후에 추가적으로 파악한 기능이 있으면 포스팅하도록 하겠다.
마무리,,
정말 유명하고 많이들 사용한 LLaMA-Factory 를 이제야 확인한게 다소 늦은감이 없잖아 있다.
그리고 요즘엔 LLM 의 연구 방향이 LLM-Agent 로 향하고 있는데 유행에 뒤쳐지고 있다는 생각도 한다.
EduTech 산업으로 와서 NLP 관련 연구 F/U 이 늦어지는건 당연하긴 하지만 아쉬운 점도 많다.
나는 출발점도 현재 정체성도 NLP 연구원이라고 생각하기 때문이다.
어느 산업에 있든 LLM 은 선택이 아닌 필수가 되어가고 있다.
부지런히 F/U 하여 NLP 연구원으로서 정체성을 지키려한다.
'Python > 패키지 훓어보기' 카테고리의 다른 글
| [PyTorch-Lightning: v2.5.1] LightningDataModule class 파악 (0) | 2025.04.18 |
|---|---|
| [PyTorch-Lightning: v2.5.1] LightningModule class 파악 (0) | 2025.04.17 |
| [PyTorch] nn.Transformer 모델 구조 상세 확인 (0) | 2025.03.12 |
| [LLaMA-Factory] LoRA Adapter 확인 (0) | 2025.02.27 |
| [LLaMA-Factory] Tokenizer padding_side 확인 (0) | 2025.02.22 |




댓글