SAINT 는 Riiid AI Research team 에서 2020년 2월 14일에 투고한 논문으로 학생의 지식 수준을 측정하는 목적의 Deep Learning Model 에 관한 내용이다.
Transformer architecture 를 기반으로 Knowledge Tracing task 를 수행하였다.
본 포스팅을 읽기 전에 필자가 이론편으로 업로드한 SAINT 와 SAINT+ 에 대해 먼저 확인하는 걸 추천한다.
1. SAINT 논문 이론 링크 바로가기
2. SAINT+ 논문 이론 링크 바로가
목차
1. 코드 재현을 위해 참고한 링크 소개
2. 데이터셋 소개
3. 데이터 Input 형태 확인
4. 모델 구조
5. 필자 리뷰
1. 코드 재현을 위해 참고한 링크 소개
먼저 필자가 재직하는 회사의 개발 서버는 cuda version 이 매우 낮아 SAINT 저자가 배포한 github 코드로는 재현이 어려웠다. 토치 라이트닝이 cuda version 에 의해 사용이 제한되었기 때문이다.
어떻게 적은 공수로 SAINT 모델을 재현할 수 있을까? 찾아보다가 케글 컴페티션에 뤼이드 데이터를 활용하여 SAINT 를 구현한 코드를 발견하였다.
해당 코드를 개발 서버 환경에 맞춰 일부 수정한 뒤, SAINT 모델을 재현할 수 있었다.
하여 어떤 코드를 참고하였는지 링크를 소개하고자 한다.
- SAINT github 링크: https://github.com/arshadshk/SAINT-pytorch/tree/main
- 케글 컴페티션 뤼이드 데이터 링크: https://www.kaggle.com/competitions/riiid-test-answer-prediction/data?select=questions.csv
- 데이터 전처리 링크: https://www.kaggle.com/code/its7171/cv-strategy
- SAINT Model 재현 링크: https://www.kaggle.com/code/abdessalemboukil/saint-training-inference-guide-39th-solution
해당 코드들을 분석하여 사용하기 편한 형태로 재구성하였다.
본 포스팅은 필자가 분석한 코드를 기반으로 작성되었음을 유의하기 바란다.
2. 데이터셋 소개
데이터셋 arguments 는 어떠한지, 학습 및 검증 데이터 구성이 어떻게 되었는지 먼저 소개하겠다.
데이터셋 arguments
- max_seq_length: 100
- batch_size: 512
- 문제 별 객관식 보기 개수: 4개 (토익 문제이기 때문)
- 객관식 보기 선택 PAD token id: 4 (index 0~3 까지 4개이기 때문에 pad 는 4)
- 정오답 여부 PAD token id: 2 (정답은 1, 오답은 0)
학습 및 검증 데이터 구성
- 학습 데이터
- 100개 이상의 시퀀스를 가진 사용자만 학습 데이터에 선정 (pad 없음)
- 검증 데이터
- 100개 이상의 시퀀스를 가진 사용자는 무작위로 선택되어 마지막 100개의 interaction 으로 제한
- 이러한 검증 방식은 약간 편향되어 있음을 주의
데이터셋 예시
array([5692, 5716, 128, 7860, 7922, 156, 51, 50, 7896, 7863, 152,
104, 108, 7900, 7901, 7971, 25, 183, 7926, 7927, 4, 7984,
45, 185, 55, 7876, 6, 172, 7898, 175, 100, 7859, 57,
7948, 151, 167, 7897, 7882, 7962, 1278, 2065, 2064, 2063, 3363,
3365, 3364], dtype=int16)- 학생이 문제를 푼 문제 id 들에 대한 sequence 정보 (a.k.a x, src)
- 문제 id 는 question.csv 파일의 question_id 를 통해 문제의 메타 정보 확인 가능
array([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 1, 1, 1, 1, 0, 1, 1, 0, 0,
0, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 0, 0,
0, 1], dtype=int8)- 학생이 해당 문제를 맞췄는지 틀렸는지 정보 (a.k.a y, trg)
- 맞았으면 1, 틀렸으면 0
array([ 0, 56, 60, 12, 6, 19, 19, 18, 18, 18, 24, 24, 22, 25, 24, 23, 21,
19, 19, 31, 21, 20, 23, 23, 17, 22, 23, 23, 25, 22, 17, 22, 61, 32,
31, 36, 38, 55, 53, 69, 60, 0, 0, 60, 0, 0], dtype=int8)- 학생이 해당 문제를 푸는데 시간이 얼마나 걸렸는지에 대한 정보 (a.k.a ts)
- time_stamp 로 60이 넘어가는 경우, 범주형태로 변경
- ex) 61, 121, 601, 1801, …
array([3, 2, 0, 0, 1, 2, 0, 3, 2, 0, 2, 1, 1, 0, 1, 2, 1, 0, 1, 3, 1, 3,
2, 3, 3, 3, 2, 1, 2, 0, 0, 3, 0, 0, 3, 2, 3, 2, 3, 3, 2, 1, 3, 1,
0, 1], dtype=int8)- 객관식 문제에 대해 학생이 어떤 답변을 선택했는지 정보 (a.k.a user_answer)
그럼 이제부터 이러한 데이터가 모델에 Input 으로 어떻게 입력되는지 형태를 확인해보겠다.
3. 데이터 Input 형태 확인
Encoder Input
학생이 문제를 푼 문제 id 들에 대한 sequence 정보를 확인해보자.
# Shape: [100, 512] -> [seq, batch]
(Pdb) src
tensor([[ 6766, 1751, 3, ..., 3440, 5953, 5668],
[ 6609, 1753, 4, ..., 3530, 5045, 4147],
[ 6612, 1752, 7870, ..., 3529, 5257, 4533],
...,
[ 3178, 4188, 1592, ..., 3812, 5012, 3713],
[ 2937, 3641, 1828, ..., 4537, 9996, 9564],
[ 2938, 10209, 1826, ..., 4258, 3762, 4419]], device='cuda:0')
문제 id 의 순서에 따라 맵핑되는 개념 id 들에 대한 sequence 정보를 확인해보자.
해당 값은 나중에 문제 id 를 개념으로 변환하여 embedding 한 값과 문제 id를 embedding 한 값을 병합해 사용한다.
# Shape: [100, 512] -> [seq, batch]
(Pdb) self.part_arr[src]
tensor([[6, 5, 5, ..., 2, 4, 2],
[6, 5, 5, ..., 2, 4, 2],
[6, 5, 5, ..., 2, 4, 2],
...,
[5, 2, 6, ..., 1, 5, 5],
[5, 5, 6, ..., 1, 5, 5],
[5, 5, 6, ..., 1, 5, 5]], device='cuda:0')
Decoder Input
학생이 해당 문제를 맞췄는지 틀렸는지 정오답 정보이다.
# shape: [100, 512] -> [seq, batch]
(Pdb) trg
tensor([[2, 2, 2, ..., 2, 2, 2], # trg[0] 값은 전부 2 : pad(정답 시작 토큰) 처리를 의미함
[1, 1, 1, ..., 1, 1, 1],
[1, 1, 1, ..., 0, 1, 1],
...,
[1, 0, 1, ..., 0, 0, 0],
[0, 1, 1, ..., 1, 0, 1],
[1, 0, 1, ..., 0, 0, 0]], device='cuda:0')
학생이 해당 문제를 푸는데 시간이 얼마나 결렸는지에 대한 정보이다. (SAINT+ 에서 활용)
# shape: [100, 512] -> [seq, batch]
(Pdb) ts
tensor([[ 0, 61, 26, ..., 0, 24, 61],
[61, 0, 20, ..., 60, 33, 15],
[ 0, 0, 17, ..., 0, 43, 32],
...,
[ 0, 38, 0, ..., 54, 24, 16],
[61, 28, 61, ..., 60, 32, 33],
[ 0, 61, 0, ..., 61, 18, 23]], device='cuda:0')
Decoder input 인 trg 와 user_answer 의 경우, 모델에 input 으로 넣어줄 때 아래와 같이 해줌을 주의하자.
- 맨 첫 번째 index 에 pad_id 추가 (trg 의 경우 2, user_answer 의 경우 4)
- 모델에 input 으로 넣어줄 때 맨 마지막 index 를 제거함 (ex. trg[:-1, :], user_answer[:-1, :])
- 이는 학생이 마지막에 풀 문제에 대한 정오답 여부와 답변 내용을 제거하기 위함이자 input dim 을 맞춰주기 위함임
- 어차피 정오답 여부와 답변 내용은 상삼각행렬(torch.triu 사용)을 통해 모델이 인지하지 못하도록 유도하기 때문에 더 정확히는 input dim 을 맞춰주기 위함이 올바른 해석이라 할 수 있음
다음은 모델 구조에서 해당 Input 값들이 어떻게 연산되는지 그 의미는 무엇인지 알아보자.
4. 모델 구조
SAINT 모델의 구조는 아래와 같다.

Encoder 연산 Process 확인

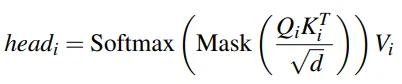

- K개의 exercise 임베딩을 입력받아 k개의 임베딩을 출력으로 뽑아 준다.
- `1`의 결과를 활용하여 동일하게 h개의 projection Q,K,V 를 생성한다.
- attention layer 에 Q,K,V를 입력받아 Q*K 통해 attention score 구한다.
- `3`의 결과를 V에 곱하기 전에 Masking을 적용하여 현재 지점을 예측함에 있어 앞의 시퀀스에만 의존하도록 제한한다.
- Mask: upper triangular 를 통해 Q*K 결과가 앞의 시퀀스에만 의존하도록 만든다.
- 음의 무한대 값으로 셋팅하여 Softmax 하면 0이 되도록하여 앞의 시퀀스에만 의존하도록 만들 수 있음
# upper triangular # shape: [seq, seq] (Pdb) mask tensor([[0., 1., 1., ..., 1., 1., 1.], [0., 0., 1., ..., 1., 1., 1.], [0., 0., 0., ..., 1., 1., 1.], ..., [0., 0., 0., ..., 0., 1., 1.], [0., 0., 0., ..., 0., 0., 1.], [0., 0., 0., ..., 0., 0., 0.]]) # upper triangular 에 음의 무한대 값으로 셋팅 for Softmax 통해 0으로 변환 # shape: [seq, seq] (Pdb) mask.masked_fill(mask==1, float('-inf')) tensor([[0., -inf, -inf, ..., -inf, -inf, -inf], [0., 0., -inf, ..., -inf, -inf, -inf], [0., 0., 0., ..., -inf, -inf, -inf], ..., [0., 0., 0., ..., 0., -inf, -inf], [0., 0., 0., ..., 0., 0., -inf], [0., 0., 0., ..., 0., 0., 0.]])
- Mask: upper triangular 를 통해 Q*K 결과가 앞의 시퀀스에만 의존하도록 만든다.
- `4`의 결과에 Softmax 하면 Masking에 의해 앞의 시퀀스 정보를 제외한 정보는 0으로 바뀐다.
- `5`의 결과에 V를 곱하여 attention이 반영된 Vector를 구한다.
- `6`의 결과를 h번만큼 반복하여 구한 multi-head를 concat하여 W0와 곱하여 input embedding dim과 동일한 크기로 맞춰준다.
- Original Transformer와 동일하게 Multi-head attention의 출력은 FFN을 거쳐 Exercises의 관계가 반영된 Vectors를 생성한다.


Decoder 연산 Process 확인


- 1개의 Start 토큰 임베딩과 k-1 개의 response embedding 을 입력 받아 k개의 predicted response 임베딩을 출력으로 뽑아 준다.(위-왼쪽 그림의 R^e)
- Encoder의 결과 벡터를 K,V로 삼고, `1`에서 구한 벡터를 Q로 지정한다.
- 단, 첫 Layer의 Q,K,V는 `1`에서 구한 벡터인 Response Embeddings이고(위-오른쪽 수식에서 M1에 해당), 그 이후의 Layer는 이전 Layer의 Output이 되어 Q로 지정한다.(위-오른쪽 수식에서 M2에 해당)
- K,V,Q에 대한 attention을 구하여 Exercise와 Response의 관계가 반영된 Vectors를 생성한다.
- 최종 Prediction Layer에서는 linear transform을 적용하고 sigmoid를 통과시켜 확률 값을 반환시켜준다.
- t-1 시점까지의 학생의 지식 상태를 근거로 t 시점의 문제를 맞출 확률을 0~1 사이의 값으로 표현
Output 형태 확인
모델의 Output 인 학생이 해당 문제에 대한 정오답 확률은 다음과 같은 형태로 주어진다.
# Shape: [100, 512, 1]
(Pdb) output
tensor([[[ 0.5378],
[ 0.2205],
[ 0.5009],
...,
[ 1.3677],
[ 0.6134],
[ 0.3285]]], device='cuda:0', grad_fn=<ViewBackward0>) - 100: Sequence
- 한 명의 학생이 문제를 푼 history 정보로 interaction 을 user_id 에 따라 sort 한 뒤 문제 풀이 시간 순서에 따라 병합한 결과
- 512: batch_size
- 512명의 학생을 의미. 즉, 학생의 수
- 1: 정오답 확률
- 해당 문제를 맞췄는지 틀렸는지를 의미
5. 필자 리뷰
SAINT 의 모델 구조는 다양한 Input 정보를 활용하는데 확장성이 매우 좋다.
문제와 관련된 정보를 Encoder 의 input 으로 활용하고, 학생의 응답과 관련된 정보를 Decoder 의 input 으로 활용할 수 있기 때문이다.
예를들어 난이도와 같은 추가적인 정보를 쉽게 추가할수 있는 구조이기에 확장성이 좋다는 필자의 의견이다.
`A Multi-Faceted Exploration Incorporating Question Difficulty in Knowledge Tracing for English Proficiency Assessment` 논문은 Encoder 정보에 난이도를 추가하여 SAINT+ 모델 구조를 확장하였다.
뤼이드는 자연어 모델인 Transformer 에 대한 깊은 이해를 바탕으로 Transformer 구조의 특징을 활용하여 학생의 지식을 예측하는 Knowledge Tracing 모델을 구현하고 성능을 통해 본인들의 서비스(산타 토익)에 적용하였다.
이를 보며 필자는 이런 생각을 한다.
Deep Learning 의 다양한 분야 중 깊은 이해를 가지고 있는 분야(ex. NLP, 추천, 비전 등)가 있다면 Task specific 한 Domain 에 대해 새로운 구조의 Deep Learning Model 을 만들 때 기 존재하는 여러 정보를 활용하면 양질의 성과를 거둘 수 있는 확률이 높다.
SAINT 가 그 예다.
NLP 중 Transformer 에 대한 깊은 이해를 가지고 EduTech Domain 에 대해 새로운 구조의 Deep Learning Model 인 SAINT 를 만들었다. 이는 기 존재하는 여러 정보(Transformer, DKT)를 잘 융합하였기 때문에 양질의 성과를 거둘 수 있었다.
필자를 이러한 인사이트를 가지고 필자가 근무하고 있는 회사 고유의 KT 모델을 만들 생각이다.
마무리,,
SAINT 모델을 직접 재현하여 확인한 적은 처음이다.
확실히 이전에 NLP 관련 연구를 만 4년 진행했어서 그런지 재현 및 해석 속도가 굉장히 빨랐다.
한... 이틀 걸렸나??
필자는 이에 만족하기 보다는 더 도전적으로 최근 유행하고 있는 LLM 관련해서 지속적으로 F/U 해야 됨을 느낀다.
Keep going 해야 한다.
만약 제가 재현한 코드가 궁금하면 댓글 달아주세요.
니즈가 많다고 판단되면 잘 안 하지만 github 에 정리해서 업로드 해서 공유드리겠습니다.
'Broad AI without NLP > Education' 카테고리의 다른 글
| [논문 리뷰] CRKT 논문 리뷰 - 코드편 (0) | 2025.01.11 |
|---|---|
| [논문 리뷰] CRKT 논문 리뷰 - 이론편 (0) | 2025.01.06 |
| [Mathpresso] 2023년도 ~4월 행보 정리 (0) | 2023.04.22 |
| [Mathpresso] 2022년도 마무리 정리 (0) | 2023.02.12 |
| [Mathpresso] 회사 및 제품의 방향성 F/U (0) | 2022.11.09 |



댓글