출처: better-tomorrow 님의 tistory
모든 창작의 시작은 모방(a.k.a 창시모)에서 나온다고 했었나..? 예전부터 Multi-GPU 용어 관련 정리를 해야겠다 생각했는데 마침 잘 정리된 글이 있어 모방한다. (말이 모방이지 사실 복붙이다...)
원본 글은 여기( link )를 참고하길 바란다.
용어
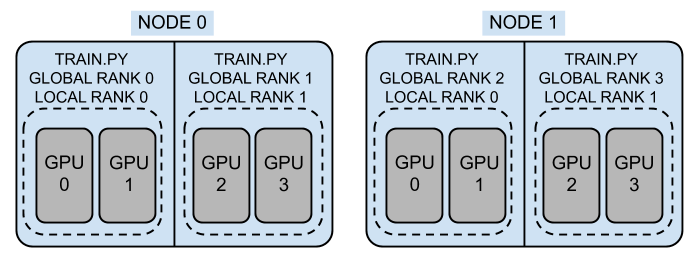
- 노드(node): 분산 처리에서는 GPU가 달려 있는 machine을 node라는 용어로 지칭
- 컴퓨터가 한 대 이면 node 1, 컴퓨터가 두 대 이면 node 2
- World Size: 작업에 사용되는 프로세스들의 개수 (즉, 분산 처리에서 사용할 총 gpu 개수)
- RANK: Rank는 Data Distributed Parallel에서 가동되는 process ID
- Global Rank: 전체 node에 가동되는 process id
- Local Rank: 각 node별 process id
- Local Rank: 노드 내 프로세스의 로컬 순위
- Local Rank 관련해서는 더 자세하게 추후에 정리가 필요할 것 같다.
함수
PyTorch를 사용하여 분산 처리 학습을 하려면 아래의 method를 사용해야 한다.
아마 Pre-train BERT 모델을 학습해 봤다면 익숙한 함수일 것이다.
torch.distributed.init_process_group()
여기서 보통 backend와, init_method, world_size, rank를 선택하는데
world_size와 rank는 위에서 언급한 것과 맞춰 넣어주면 된다.
- backend의 경우는 , Gloo, MPI, NCCL의 옵션이 있다. 보통은 NCCL이 GPU 기반 학습에서 사용하는 것이 좋다고 한다. 필자는 그것도 모르고 그냥 NCCL로 학습을 했던 기억이 있다...
- NCCL은 분산 GPU 학습 시, Gloo는 분산 CPU 학습 시, MPI는 고성능 컴퓨팅 시 필요하다고 한다.
- 여기( link )를 참고하면 더 자세한 정보를 알 수 있다.
- init_method
- URL specifying how to initialize the process group 이라고 하는데... 솔직히 뭔 소린지 모르겠다. process 계산을 위한 설정인가..?
- init method는 각 프로세스가 서로 탐색하는 방법
- 통신 backend를 사용하여 프로세스 그룹을 초기화하고 확인하는 방법을 알려준다.
- init_method가 지정되어 있지 않으면 Pytorch에서는 환경 변수 초기화 메서드(env://)를 사용
- torch.distributed.barrier
TBP
(To Be Posting 의 의미)
'널널한 개발자'라는 유튜브 채널에서 process와 같은 컴퓨팅 처리 방식을 잘 설명해준다. 추후에는 해당 유튜브에서 설명한 process를 공부할겸 포스팅하려 한다.
그리고 분산 처리 학습의 종류에는 크게 DP와 DDP가 있다. DP와 DDP가 무엇인지, 어떻게 다른지 포스팅하도록 하겠다.
반응형
'Python > Study' 카테고리의 다른 글
| [class 기능 정리] 코딩을 깔끔하게 해주는 기능 (0) | 2022.08.12 |
|---|---|
| [Super] 상속에 사용하는 Super 함수 알아보기 (0) | 2022.08.03 |
| [Overriding] 오버라이딩을 이용한 코드 수정 (0) | 2022.08.02 |
| [소개] ONNX 란? (0) | 2022.07.27 |
| [Package] 파이썬 코드 패키지화 → setup.py (0) | 2022.07.11 |


댓글