Sentence-Transformers (UKPlab)
Sentence embedding 관련 패키지 리서치 중 Sentence-Transformers Github 코드를 자세히 살펴볼 기회가 생겼다.
해당 패키지의 구조부터 자세한 상세 기능, 그리고 BERT 모델 사용 시 HuggingFace Transformers 와의 호환성까지 살펴보려 한다.
Sentence-Transformers > eval process
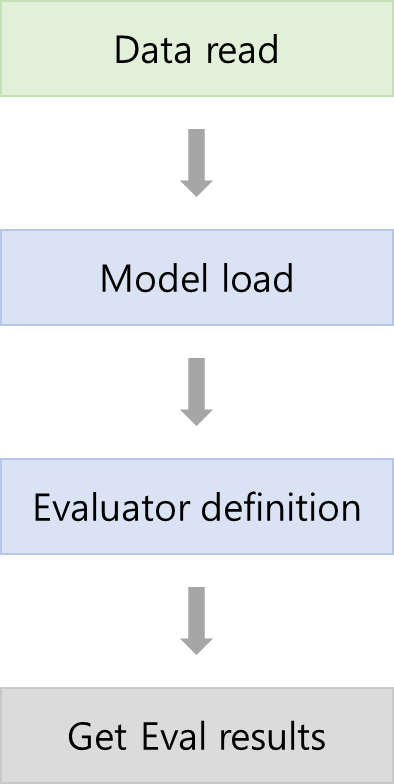
- Data read
- Eval datasets format에 맞춰 read - Model load
- Sentence_Transformers로 학습된 모델 불러오기
- 만약 Sentence_Transformers로 학습되지 않았다면 Eval 불가능 - Evaluator definition
- Evaluation 폴더에 있는 evaluate 객체 정의
- 데이터셋에 따라 구하고자 하는 metric이 다르기 때문에 evaluate 방법 선택 시 주의
ex. LabelAccuracyEvaluator의 경우, NLI datasets 사용해서 accuracy만 구함 - Get Eval results
- 3번에 의존하는 결과 값(metric) 저장
Sentence-Transformers > pred process
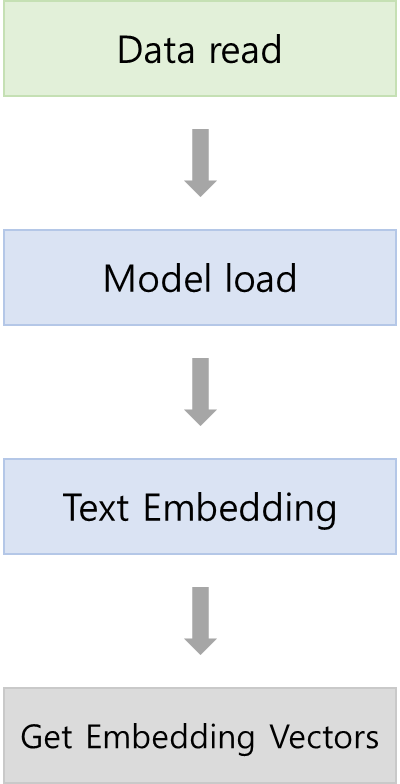
- Data read
- Pred datasets format에 맞춰 read - Model load
- Sentence_Transformers로 학습된 모델 불러오기
- 만약 Sentence_Transformers로 학습되지 않았다면 Eval 불가능 - Text Embedding
- 2번에서 불러온 Model의 내장 함수인 "encode" function을 사용해서 Pred datasets인 Text를 Embedding - Get Embedding Vectors
- 3번 결과를 활용해서 원하는 task에 맞게 사용
Sentence Embedding 값은 폭 넓게 사용할 수 있기 때문에 본인이 하고자 하는 task에 따라 유동적으로 사용하면 된다. 대표적인 예시로는 clustering과 유사 문장 찾기가 있다.
Comments
Sentence-Transformer의 기능 중 Evaluator를 사용하다 보면 본인이 원하는 metric 값이 없는 Evaluator가 있을 수 있다. 또한 Evaluator 안에 Loss class를 넣어줘야만 동작하는 경우도 있다.
다음 포스팅은 sentence-transformers 상세 기능에 대해 살펴볼 예정이다.
학습 Process검증 및 예측 Process- sentence-transformers 상세 기능
- HuggingFace transformers와 어떻게 다른지
To Be Continued.....
반응형
'Natural Language Processing > Github 훑어보기' 카테고리의 다른 글
| [Code review] Sentence-Transformers 비교 hug/trans (0) | 2022.07.08 |
|---|---|
| [Code review] Sentence-Transformers 상세 기능 (0) | 2022.07.08 |
| [Code review] Sentence-Transformers 학습 Process (0) | 2022.07.05 |
| [Code review] Sentence-Transformers 훑어보기: 구조 (0) | 2022.07.04 |



댓글