들어가며..
현대를 살아는 대부분의 사람들이 자주 접하는 AI 기술은 챗봇이지 않을까? 챗봇 기술은 대부분 작은 기기에 내장되어 동작한다. 우리가 흔히 접할 수 있는 예로는 '인공지능 스피커', '시리', '빅스비' 등이 있다. 인공지능을 자주 접한 사람, 그 중 초거대 언어 모델에 대해 조금이라도 들어본 사람이라면 이런 의문이 들 수 있다. '아니 이렇게 작은 기기에서 어떻게 챗봇이 동작할 수 있을까?' 이 의문의 답이 바로 본 포스팅에서 소개할 'Deep Learning Compiler' 이다.
초거대 언어 모델이란?
필자가 포스팅한 아래 링크를 참고하길 바란다.
https://beeny-ds.tistory.com/21
[소개] 초거대 언어 모델이란?
들어가며.. 최근 여러 대기업에서 자신들이 만든 초거대 언어 모델을 소개하며 홍보하는 걸 자주 접할 수 있다. 물론 해당 분야에 관심이 있는 사람들만 접할 수 있었겠지만 본 포스팅을 읽는
beeny-ds.tistory.com
Deep Learning Compiler 란?
딥러닝 모델을 특정 device 상에서 효율적으로 동작시키기 위해서는 동작시킬 딥러닝 모델을, 타겟 device에서 최적의 속도와 정확도를 낼 수 있는 머신 코드로 변환 해야 한다. 이러한 코드 변환 작업을 자동으로 지원해주는 도구를, ‘Deep Learning Compiler’라고 한다.
woono님의 블로그 글 인용
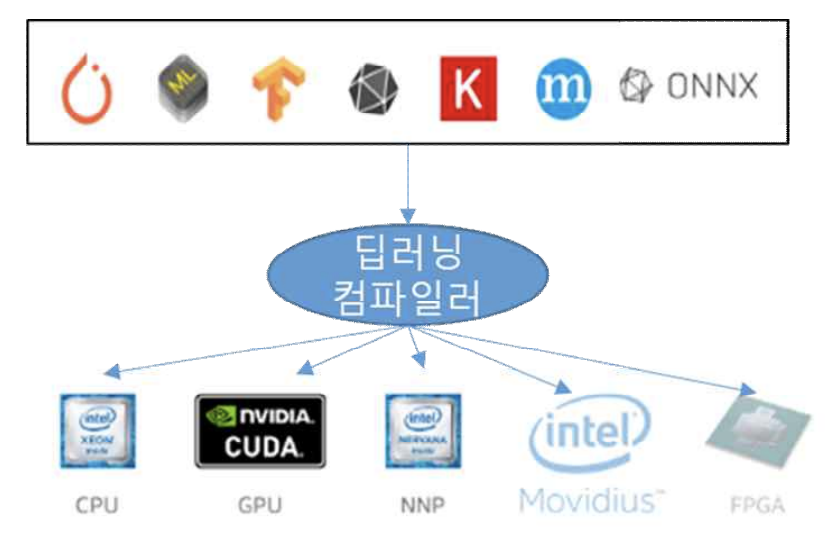
woono 님의 블로그에서 인용한 설명을 해석해보자.
- 특정 device 란 무엇일까?
- device는 여러 개의 종류가 있다. 컴퓨터에서 cpu와 gpu는 동작 방식이 다르듯 모바일 환경을 이루고 있는 device 또한 동작 방식이 다르다.
- 이처럼 특정 device란 사용자가 사용하는 환경에 따라 다양한 종류를 가질 수 있다.
- 딥러닝 모델을 왜 특정 device 에서 효율적으로 동작시킨다고 한 걸까?
- 필자가 경험한 딥러닝 모델은 대부분 Python 프로그램으로 학습시켜 배포한다.
- Python에서 딥러닝 모델을 학습시키는 모듈은 여러 종류가 있다.
[PyTorch, Tensorflow, Keras, ONNX, etc...] 를 딥러닝 프레임워크 라고 한다. - 딥러닝 프레임워크는 환경(⊃device)에 따라 동작하는 방식이 다를 뿐만 아니라 성능과 속도 또한 다르다.
- 딥러닝 프레임워크를 특정 환경에 맞춰 효율적으로 동작시키기 위해서는 변환이 필요하다.
- 머신 코드 변환이 무엇인가?
- 2번에서 말한 딥러닝 프레임워크를 특정 환경에 맞춰 효율으로 동작 시키기 위한 변환이다.
- 변환은 '딥러닝 프레임워크' → '딥러닝 컴파일러' 를 뜻한다.
- 머신 코드 변환으로 딥러닝 모델이 특정 device 에서 효율적으로 동작하면 무엇이 좋을까?
- 빠른 계산 속도: 딥러닝 프레임워크로 동작하는 속도보다 더 빨라진다.
- (소량의)성능 개선: 이건 case by case 이지만... 계산 속도가 빨라지는데 성능이 유지되거나 개선되기도 한다.
- 호환성: 딥러닝 프레임워크 형태로는 특정 device에서 동작하지 않지만 딥러닝 컴파일러 형태로는 동작하는 경우가 많다.
Deep Learning Compiler 의 종류
- TFLite
- TensorFlow(Keras)의 모델만 최적화가 가능
- 여러 하드웨어에서 추론이 가능
- 타겟 하드웨어에 따른 추가적인 최적화는 없음
- TensorRT
- 다양한 프레임워크의 모델 최적화가 가능
- NVIDIA GPU 만 추론 하드웨어로 사용 가능
- 추론에 사용하려는 NVIDIA GPU 종류에 따라 추가적으로 최적화할 수 있음
- TVM
- 다양한 프레임워크의 모델 최적화가 가능
- 여러 하드웨어에서 추론이 가능
- 추론에 사용하려는 하드웨어 종류에 따라 추가적으로 최적화할 수 있음
필자의 의견
최근 NVIDIA에서 '딥 러닝 모델 학습을 위한 End-to-End 가속화 기술' 이란 이름으로 여러 기술을 소개했다. 소개한 내용 중 하나가 딥러닝 컴파일러이다. 인공지능(⊃딥러닝)을 사용하기 위해서 꼭 필요한 기술 중 하나가 딥러닝 컴파일러라고 생각한다.
딥러닝 프레임워크를 딥러닝 컴파일러로 변환할 때 딥러닝 프레임워크의 형태를 ONNX로 고정하는 것이 좋다. 왜 그런지는 다음 포스팅 때 소개하도록 하겠다.
만약 자신이 데이터 분석가라면, 데이터 사이언티스트라면 꼭 딥러닝 컴파일러에 관해서, 모델 서빙에 관해서 공부하는 걸 추천한다. 데이터 분석가, 사이언티스트가 하는 일은 결국 우리가 만든 인공지능을 사용자가 사용할 수 있도록 제공하는 일이기 때문이다. 필자도 올해 초부터 그것을 깨닫고 조금씩 공부하고 있다. 물론... 진짜 조오금씩 이지만...
To Be Continued
댓글