LLM 을 통해 생성된 답변의 성능을 평가하는건 어려운 Task 이다.
현재 평가 방법으로는 성능이 좋은 LLM 모델을 통해 평가하는 방법(LLM-as-a-judge, Pheonix, RAGAS, DeepEval)은 많지만 해당 평가 방법을 프로젝트에 적용시키기는 쉽지 않다.
본 포스팅은 프로젝트에 가장 많이 활용되는 RAG Process 의 생성 답변 성능을 RAGAS 로 평가하는 과정과 그 결과에 대해 다루도록 한다.
RAGAS 의 성능 근거를 확인하기 위해 LangSmith 를 통해 Log 를 확인한 결과도 다루겠다.
※ sLLM 에 대한 연구를 하는 사람에게 도움이 되는 글임을 유의하길 바란다.
목차
1. 사용 결과 피드백
2. 환경 설정
3. 평가할 데이터 Load
4. 모델 평가
5. 성능 평가 근거 확인
1. 사용 결과 피드백
늘 시간이 부족한 현대인을 위해 사용 후기(피드백)를 먼저 공개한다.
- 성능 평가 결과에 대한 근거(=reason)를 확인 가능하지만 영어로 되어 있어 상세한 확인이 불편
- Domain specific context-QA(ex. RAG) 에서는 문맥을 파악하여 질문에 대한 명확한 답을 도출해내는 능력이 부족
- 질문에 명확한 키워드 없이 유추해야 답변할 수 있는 경우, 성능 신뢰도가 떨어짐
- ragas 로 평가할 때 제공하는 default prompt template 이 평가하고자 하는 task 와 mapping 되지 않아 성능 신뢰도가 떨어지는 것으로 보임
- 직접 prompt template 을 구성해서 g-eval 로 평가하는게 더 높은 신뢰성을 가질 것으로 판단됨.
- g-eval 할 때 ragas 에서 제공하는 default prompt template 을 참고할 수 있을 것으로 보임
2. 환경 설정
LangSmith 활용하여 Log 확인을 위해서는 API_KEY & Project 생성을 해야 한다.
LangSmith 링크참고
a. API KEY 발급
- Settings 에서 API Keys > Create API Key 눌러 발급받자.

API Key 발급 방법
b. New Project 생성
- Projects 에서 New Project 생성
- Python 에서 환경 설정으로 New Project 생성

import os
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_PROJECT"] = {your-create_project_name}
os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com"
os.environ["LANGCHAIN_API_KEY"] = "{your-api_key}"
추가적으로 OpenAI Api Key 도 입력해주자. (RAGAS 사용 시 gpt-4o-mini 가 default 로 성능 평가에 사용된다.)
os.environ["OPENAI_API_KEY"] = {openai_key}
3. 평가할 데이터 Load
준비물은 Context, Question 에 대한 모델의 생성 결과인 Answer 이다.
편의상 모델의 생성 결과는 Gen_Answer 로 표기하겠다.
성능으로는 대표적으로 2가지 지표를 많이 사용한다.
faithfulness 와 answer_correctness 이다.
해당 성능에 대한 상세한 설명은 3. 모델 평가에서 상세히 다루도록 하겠다.
그럼 Gen_Answer 와 Question, Context, GT_Answer(기대하는 정답 결과) 를 불러오자.
import pandas as pd
from datasets import Dataset
df = pd.read_excel('gen_outputs.xlsx', sheet_name = 0)
index = 26
context = df.context[index]
question = df.question[index]
answer = df.gen_answer[index]
ground_truth = df.gt_answer[index]
data_samples = {
'question': [question],
'answer': [answer],
'contexts': [[context]],
'ground_truth': [ground_truth]
}
dataset = Dataset.from_dict(data_samples)
4. 모델 평가
평가하기에 앞서 faithfulness 와 answer_correctness 가 어떤 지표인지 알아보자.
- faithfulness: 주어진 문맥에 대한 생성된 답변의 사실적 일관성을 측정
- 생성된 답변(gen_answer)과 검색된 문맥(context)을 기준으로 계산
- 생성된 답변이 신뢰할 수 있다고 간주되려면 답변에서 제시된 모든 주장이 주어진 문맥에서 추론될 수 있어야 됨
- 생성된 답변을 개별 주장으로 나눔
- 각 주장이 검색 결과로부터 추론 가능한지 확인
- 추론 가능한 주장의 수를 전체 주장 수로 나누어 점수를 계산
- 성능은 (0, 1) 범위. 값이 높을수록 좋은 성능
- 공식은 아래 Faithfulness score 참고
- answer_correctness: 사실적 정확도와 의미적 유사도의 가중 평균을 계산하여 최종 점수를 도출 (F1 Score)
- 답변(answer)과 정답(gt answer)을 기준으로 (의미적 유사도) 계산
- 사실적 정확도 계산
- TP (진양성): 정답과 생성된 답변 모두에 존재하는 사실
- FP (위양성): 생성된 답변에만 존재하는 사실
- FN (위음성): 정답에만 존재하는 사실
- 성능은 (0, 1) 범위. 값이 높을수록 좋은 성능
- 공식은 아래 Faithfulness score 참고
코드는 매우 간단하다.
from ragas import evaluate
from ragas.metrics import faithfulness, answer_correctness
result = evaluate(
dataset,
metrics = [faithfulness,answer_correctness]
)
result
# ourput
# {'faithfulness': 1.0000, 'answer_correctness': 0.5443}result 는 DataFrame 형태로도 볼 수 있다.

필자가 사용한 데이터는 AI Hub 에서 배포한 `숫자연산 기계독해 데이터`이다.
gt_answer 는 gpt-4o 를 통해 1shot 을 주고 생성하였다.
상세한 question , gen_answer, context, gt_answer 는 본 포스팅 맨 아래에서 확인하기 바란다.
5. 성능 평가 근거 확인
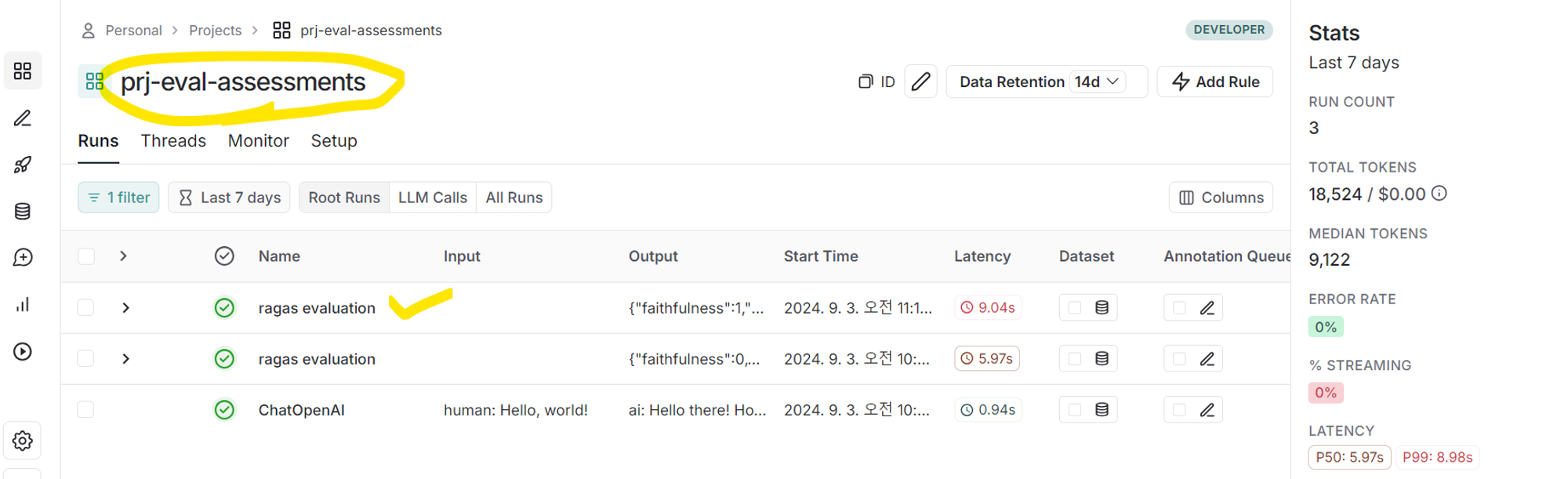
Faithfulness 와 Answer_correctness 성능의 근거는 LangSmith 에서 생성한 Project 에서 확인할 수 있다.
해당 Project 에 들어가보면 실행한 trial 마다 Log 를 확인할 수 있다.(왼쪽 사진)
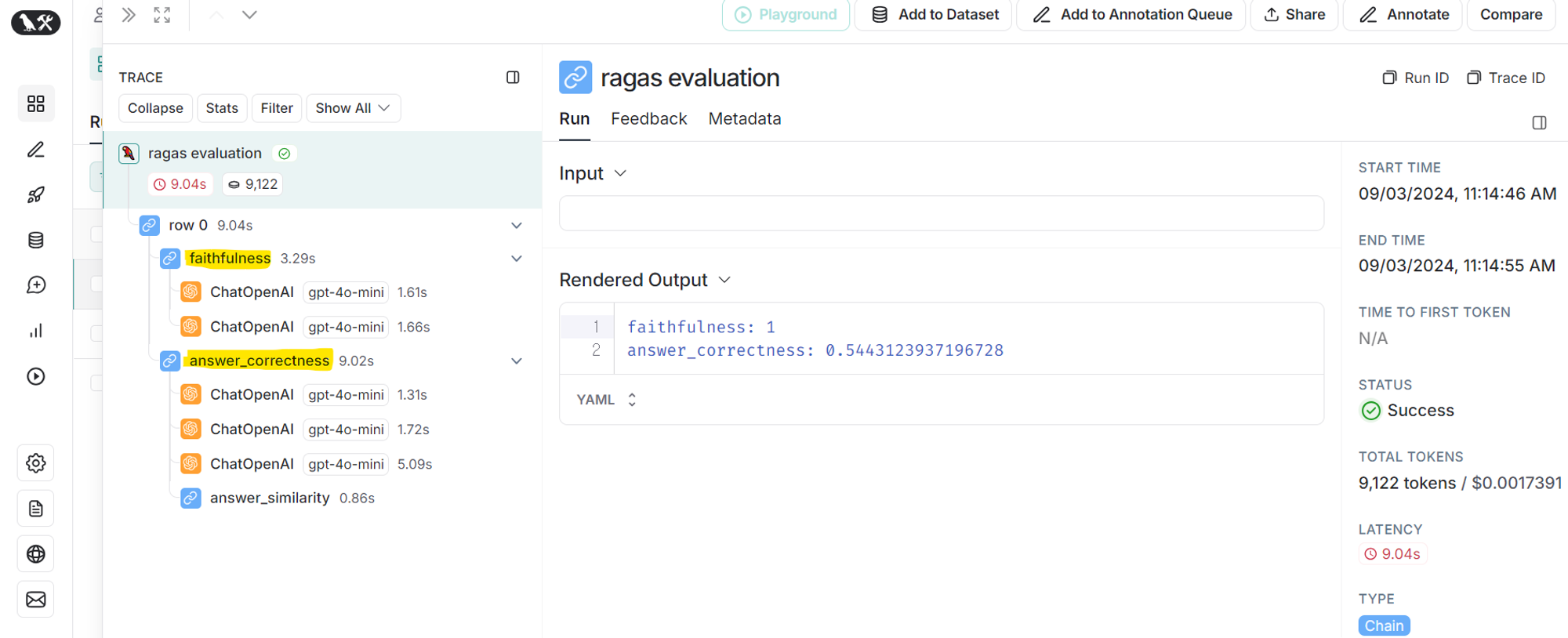
방금 실행한 trial 로 들어가보면 2개의 성능 평가를 어떤 Process 로 했는지 확인할 수 있다.(오른쪽 사진)
성능 평가는 gpt-4o-mini 를 사용하고, faithfulness 는 2번 gpt를 활용하여 성능 도출 / answer_correctness 는 3번 gpt를 활용하여 성능 도출 한다. 이제 하나하나 상세하게 살펴보자.
a. faithfulness detail
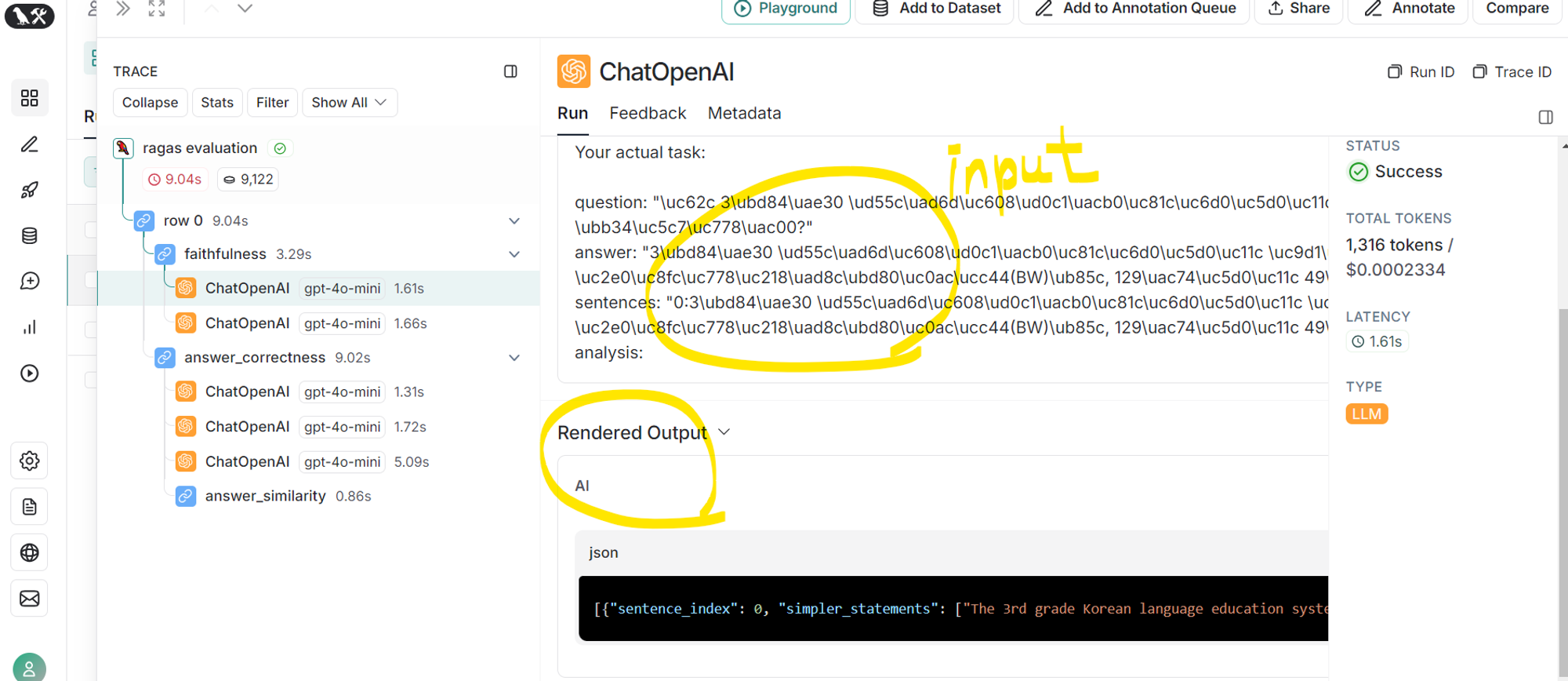
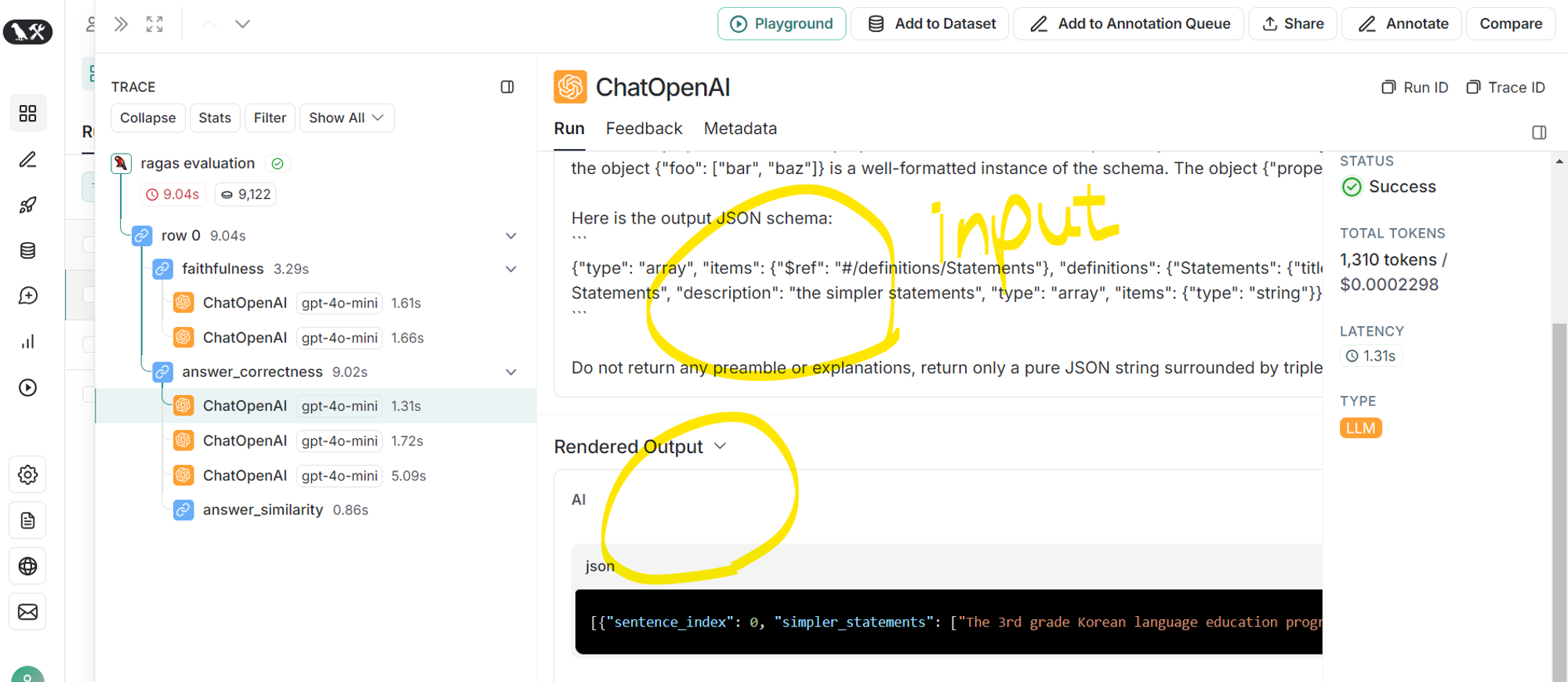
- 생성된 답변을 개별 주장으로 나눔
- input prompt 확인 가능(왼쪽 사진)
-
더보기
- # 3개의 주장으로 나눈 결과
[{
"sentence_index": 0,
"simpler_statements": [
"The 3rd grade Korean language education system has been implemented in the 3rd grade.",
"The 3rd grade Korean language education system is currently being evaluated.",
"The evaluation results indicate that the performance level is 62.0% based on 49 out of 129 students."]
}
]
- # 3개의 주장으로 나눈 결과
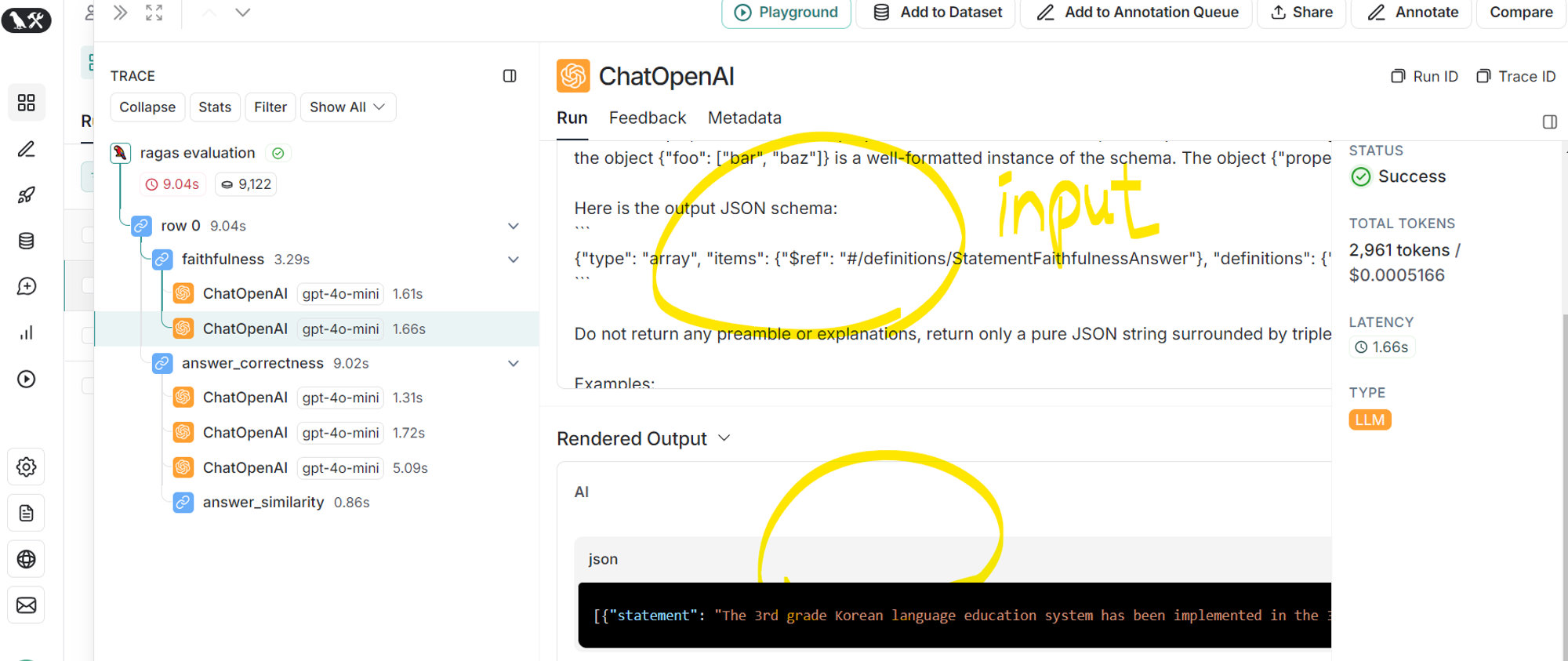
- 각 주장이 검색 결과로부터 추론 가능한지 확인 및 점수 계산
- input prompt 확인 가능(오른쪽 사진)
-
더보기# 3개의 주장에 대한 결과 확인
# verdict 이 1이면 검색 결과로부터 추론 가능하다는 의미 0이면 불가능하다는 의미
# 3개의 값을 통해 점수 계산
[{
"statement": "The 3rd grade Korean language education system has been implemented in the 3rd grade.",
"reason": "The context states that the 3rd grade Korean language education system has been implemented, which directly supports this statement.",
"verdict": 1
}, {
"statement": "The 3rd grade Korean language education system is currently being evaluated.",
"reason": "The context discusses evaluation results, indicating that the system is indeed being evaluated.",
"verdict": 1
}, {
"statement": "The evaluation results indicate that the performance level is 62.0% based on 49 out of 129 students.",
"reason": "The context provides specific performance levels and student counts, confirming this statement as accurate.",
"verdict": 1
}
]
b. answer_correctness detail
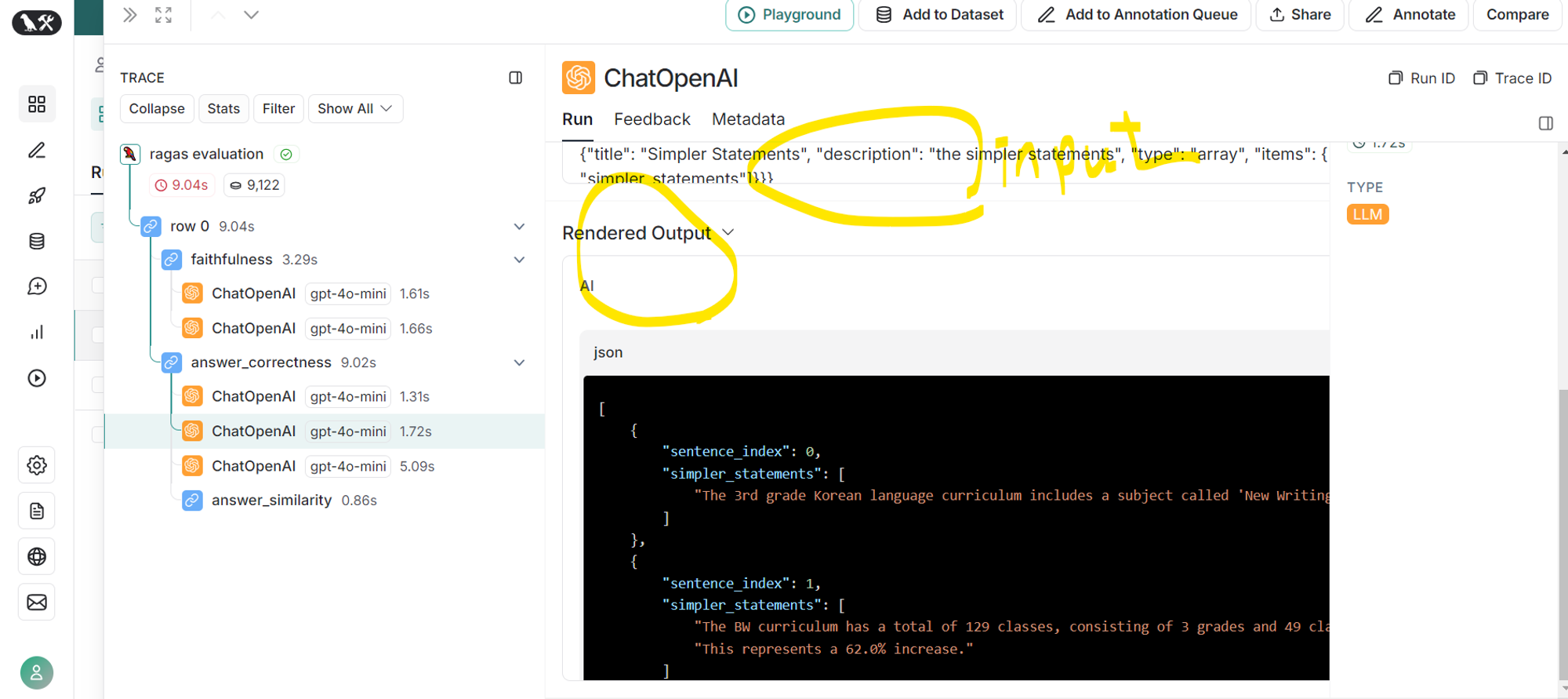
- 생성된 답변을 하나 이상의 문장으로 분해
- input prompt 확인 가능 (왼쪽 사진)
-
더보기# 생성된 답변(gen_answer)을 분해 for 비교
[{
"sentence_index": 0,
"simpler_statements": [
"The 3rd grade Korean language education program has been implemented.",
"The implementation of the program has resulted in a significant increase in student performance.",
"The increase in student performance is measured at 62.0% based on 49 out of 129 students."
]
}]
- ground truth 답변을 하나 이상의 문장으로 분해
- input prompt 확인 가능 (중앙 사진)
-
더보기# 정답이 되는 답변(gt_answer)을 분해 for 비교
[
{
"sentence_index": 0,
"simpler_statements": [
"The 3rd grade Korean language curriculum includes a subject called 'New Writing Ability (BW)'."
]
},
{
"sentence_index": 1,
"simpler_statements": [
"The BW curriculum has a total of 129 classes, consisting of 3 grades and 49 classes.",
"This represents a 62.0% increase."
]
},
{
"sentence_index": 2,
"simpler_statements": [
"This is a significant increase in the curriculum of the previous type of writing subject (CB) and the development subject (EB).",
"The increase is expected to be substantial."
]
}
]
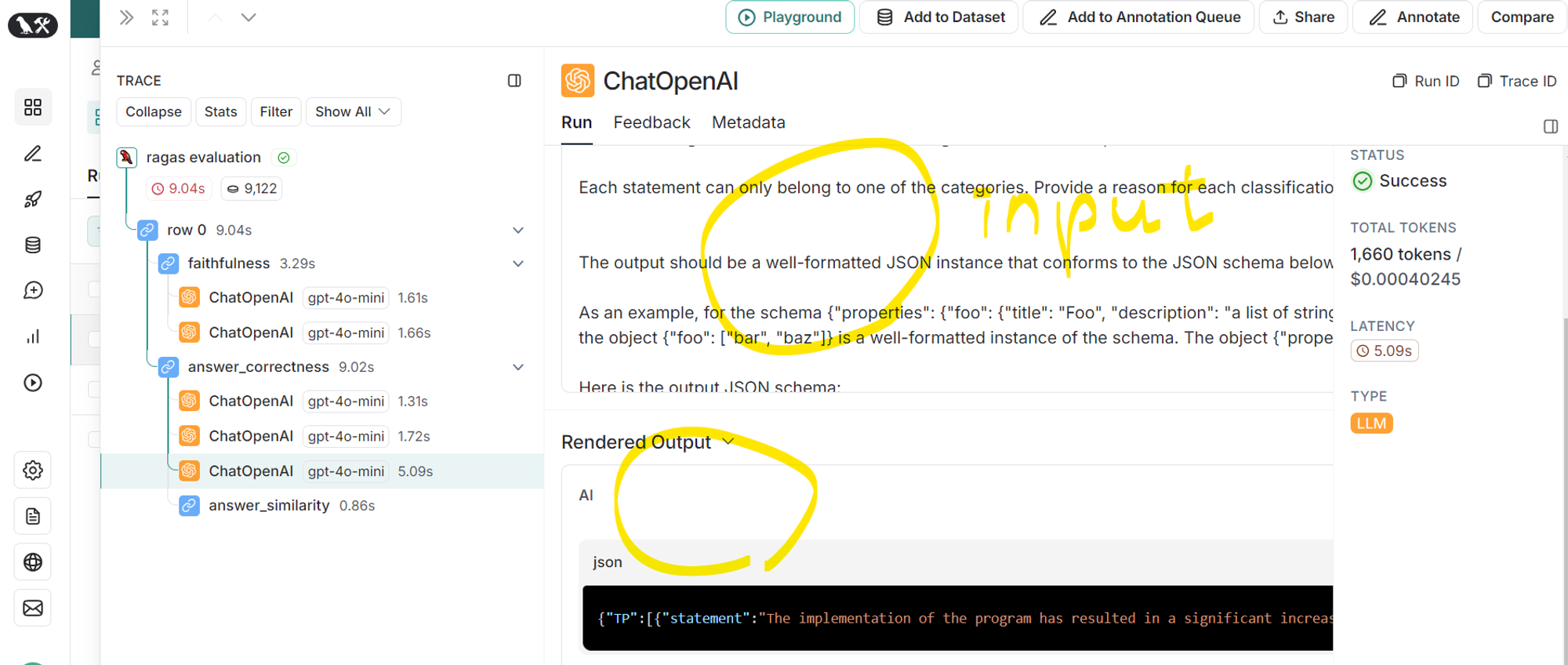
- 1번, 2번에서 구한 ground truth 진술과 answer 진술을 분석하여 TP, FP, FN 범주 중 하나로 분류 후 성능 도출
- input prompt 확인 가능 (오른쪽 사진)
-
더보기# TP, FP, FN 범주 중 하나로 분류 후 성능 도출
# reason 을 통해 근거 확인 가능
{
"TP": [{
"statement": "The implementation of the program has resulted in a significant increase in student performance.",
"reason": "This statement is supported by the ground truth which mentions a significant increase in performance."
}, {
"statement": "The increase in student performance is measured at 62.0% based on 49 out of 129 students.",
"reason": "This statement is directly supported by the ground truth that states a 62.0% increase."
}
],
"FP": [{
"statement": "The 3rd grade Korean language education program has been implemented.",
"reason": "While this statement is plausible, it is not directly supported by the ground truth, which discusses the curriculum but does not confirm its implementation."
}
],
"FN": [{
"statement": "The 3rd grade Korean language curriculum includes a subject called 'New Writing Ability (BW)'.",
"reason": "This important detail about the curriculum is not mentioned in the answer."
}, {
"statement": "The BW curriculum has a total of 129 classes, consisting of 3 grades and 49 classes.",
"reason": "This specific information about the structure of the curriculum is missing from the answer."
}, {
"statement": "This represents a 62.0% increase.",
"reason": "Although the percentage is mentioned in the answer, the context of it being a representation of the increase is not included."
}, {
"statement": "This is a significant increase in the curriculum of the previous type of writing subject (CB) and the development subject (EB).",
"reason": "The answer does not address the comparison to previous subjects, which is a key aspect of the ground truth."
}, {
"statement": "The increase is expected to be substantial.",
"reason": "This expectation of substantial increase is not reflected in the answer."
}
]
}
실제로 사용해보면 Input Log 를 통해 어떤 Prompt 를 넣어 결과를 도출하는지 확인할 수 있다.
g-eval 을 통해 LLM 의 성능을 평가하고자 한다면 해당 Prompt 를 참고해도 좋을 듯 하다.
마무리,,
플젝에 적용해보기 위해 RAG 를 위한 Context, Question 에 대한 Answer 의 성능 평가를 해봤다.
결과는... 매우 아쉽지만 g-eval 에 비해 신뢰할만한 결과는 나오지 않았다.
그래도 하나 건진건 g-eval 을 위한 Prompt 를 LangSmith 를 통해 고도화했다는 점이다.
흠.... 매번 Human eval 을 할 수도 없고... 이러저러한 방법을 시도해봐야겠다는 생각으로 포스팅을 마친다.
ps. 예시로 사용한 Context, Question 을 공개한다.
# Context
올 3분기 한국예탁결제원을 통한 주식관련사채의 권리행사가 직전 분기 대비 감소한 것으로 집계됐다.
11일 한국예탁결제원에 따르면, 3분기 주식관련사채의 행사 건수와 행사금액은 각각 353건, 2,681억원으로 나타났다. 이는 전분기 대비 35.7%, 37.4% 각각 감소한 수준이다. 주식관련사채란, 전환사채(CB)·교환사채(EB)·신주인수권부사채(BW) 등 발행 시 정해진 일정한 조건(행사가액·행사기간 등)으로 발행사의 주식 또는 발행사가 담보한 타 회사의 주식으로 전환 또는 교환이 가능한 채권을 말한다.
예탁원 측은 대외시장의 복합적 요인 등으로 국내 증권시장의 혼조세가 이어진 것을 권리행사 감소의 배경으로 꼽았다. 주식관련사채 발행 기업의 주가가 행사가격을 하회하면서 권리행사가 줄었다는 설명이다.
종류별로는 CB가 288건으로 직전분기(397건) 대비 27.4%, EB가 16건으로 직전분기(23건) 대비 30.4%, BW는 49건으로 직전분기(129건) 대비 62.0% 각각 감소했다. 행사금액의 경우, CB가 2,109억원으로 직전분기(3,700억원) 대비 43.0%, BW가 85억원으로 직전분기(147억원) 대비 42.1% 각각 감소했다. 다만, EB는 487억원으로 직전분기(437억원) 대비 11.4% 증가했다.
EB 행사 건수가 직전분기 대비 감소한 것과 달리 행사금액은 증가한 이유에 대해 김해연 한국예탁결제원 채권권리팀 선임은 “채권을 소지한 이들 각자가 보유한 채권 금액에 따라 행사 금액이 달라질 수 있기 때문에, 행사 건수는 줄어들어도 행사금액을 증가할 수 있다”고 설명했다.
한편, 3분기 주식관련사채 행사금액 상위종목은 아난티 2회 CB(223억원), 제이콘텐트리 15회 EB(199억원), 이아이디 8회 EB(189억원) 순으로 조사됐다.
# Question
올 3분기 한국예탁결제원에서 집계된 주식관련사채 중 권리행사 건수가 직전 분기 대비 가장 많이 감소한 것은 무엇인가?
'Natural Language Processing > NLG 이모저모' 카테고리의 다른 글
| LoRA 학습 코드 예시 (1) | 2024.09.02 |
|---|---|
| LLM 을 Pretrain 학습하려면,, (3) | 2024.01.25 |
| LLAMA 모델 구조 파악 (1) | 2024.01.08 |
| LLM 학습을 위한 데이터 생성에 대하여,, (0) | 2023.12.29 |
| ChatGPT Prompt 작성 팁 (2) | 2023.12.27 |




댓글