지난 포스팅에서는 LoRA 의 기본 개념을 실무자에 맞춰 설명했다.
이번 포스팅에서는 LoRA 가 코드 단에서는 어떻게 구현되어 있는지 실무자 맞춤 요점을 설명하겠다.
수식과 이론적인 논문 리뷰를 원한다면 다른 논문 리뷰 블로그를 참고하기 바란다.
Target 독자: Deep Learning 전문가
목차
1. LoRA 에 대한 개념과 용어 사전
2. LoRA 는 어디에 있을까
3. LoRA 의 3가지 저장 형태
4. config setting
1. LoRA 에 대한 개념과 용어 사전
LoRA 에 대한 개념은 필자가 이전에 포스팅한 글을 참고하기 바란다.

LoRA 의 요점을 파악하기에 앞서 용어를 먼저 통일하겠다.
- LoRA_A : {d x r} 차원의 nn.linear
- LoRA_B : {r x k} 차원의 nn.linear
- k = d 로 가정하겠다. 왜냐하면 실제 코드에서 k 와 d 의 차원이 같기 때문이다.
- Rank r 의 차원은 d 보다 많이 작다. (r << d)
- 편의상 Model weight 에 더해주는 Matrix 는 ( LoRA_A x LoRA_B ) 라고 표현하겠다.
- LoRA_emb_A : {vocab_size x r} 차원의 nn.linear
- LoRA_emb_B : {r x d} 차원의 nn.linear
- Embedding layer 에 더해지는 embedding LoRA layer 이다. (word embedding 이라 생각하자)
- 편의상 Model weight 에 더해주는 Matrix 는 ( LoRA_emb_A x LoRA_emb_B ) 라고 표현하겠다.
- LoRA_lm-head_A : {d x r} 차원의 nn.linear
- LoRA_lm-head_B : {r x vocab_size} 차원의 nn.linear
- Decoder Model 에서 Output 을 도출하는 CLM layer 에 더해지는 LoRA layer 이다. (output dim 이 vocab_size)
- 편의상 Model weight 에 더해주는 Matrix 는 ( LoRA_lm-head_A x LoRA_lm-head_B ) 라고 표현하겠다.
- embed_tokens : Embedding layer 를 뜻한다. (word embedding 이라 생각하자)
- lm_head : Decoder Model 에서 Output 을 도출하는 CLM layer 이다. (마지막 Layer 이다.)
- q_proj : Decoder layer 에 있는 Query Layer 이다.
- v_proj : Decoder layer 에 있는 Query Layer 이다
- o_proj : Decoder layer 에 있는 Self-Attention Layer 이다
원활한 내용 전달을 위해 용어 정의가 길어진 점 양해 바란다.
하지만 이 글을 읽는 독자층은 이미 다 아는 내용이라 생각한다.
적어도 Attention is all you need 논문은 읽어봤을 거라 생각하기 때문이다.
2. LoRA 는 어디에 있을까
결론부터 말하자면 LoRA 는 Model 구조의 어디에나 있을 수 있다.
오늘날 LLM 이라 표현되는 Model 은 웬만하면 Decoder Model 이기 때문에 Decoder Model 이라 간주하고 쓰겠다.
Decoder Model 의 구조는 크게 3가지로 나눌 수 있다.

LoRA 는 어디에나 있을 수 있다는 의미는 (어디에나 있을 수 있다는 의미는 더해질 수 있다는 의미와 같다.)
- Word embedding 에 더해질 수도
- 모든 Decoder Layer 에 더해질 수도 (sLLM 의 경우, Decoder Layer 는 약 32~80 개)
- 마지막 CLM Layer 에 더해질수도
있다. 사용자가 선택하면 된다.
관련 argument 는 아래서 예시로 보여주겠다.
그렇다면 어떤 형태의 Matrix 가 Pretrain Model weight 에 더해지는지 알아보자. (용어 사전을 숙지하자.)
- Word embedding : ( LoRA_emb_A x LoRA_emb_B ) Matrix 가 더해진다. Matrix 의 차원은 {vocab_size x d} 이다.
- Decoder embedding : ( LoRA_A x LoRA_B ) Matrix 가 더해진다. Matrix 의 차원은 {d x d} 이다.
- 학습 소스 코드를 살펴보니 특정 Decoder layer 만 선택해서 LoRA Matrix 를 더해주는 건 불가능하다.
- 때문에 모든 Decoder layer 에 LoRA Matrix 를 더해줘야 한다.
- CLM layer : ( LoRA_lm-head_A x LoRA_lm-head_B ) Matrix 가 더해진다. Matrix 의 차원은 {d x vocab_size} 이다.
3. LoRA 의 3가지 저장 형태
LoRA 를 활용해서 모델을 학습하게 되면 어떤 값이 저장되는 걸까?
- 저장되는 형태는 사용자가 지정할 수 있다.
- 저장되는 형태는 3가지로 분류된다.
3가지 저장 형태를 알아보자.
a. Model architecture 에 LoRA layer 를 추가하여 저장
- Output : 모델 구조(=pytorch_model.bin)
- 특징
- Inference 시 Pretrain Model 의 연산량보다 많은 연산량이 필요하다.
- Model weight 가 증가하여 Model 이 학습 전 Pretrain Model 보다 무거워진다.
- # of Model weight 가 달라진다.
모델 구조를 보면 이렇게 되어있다.
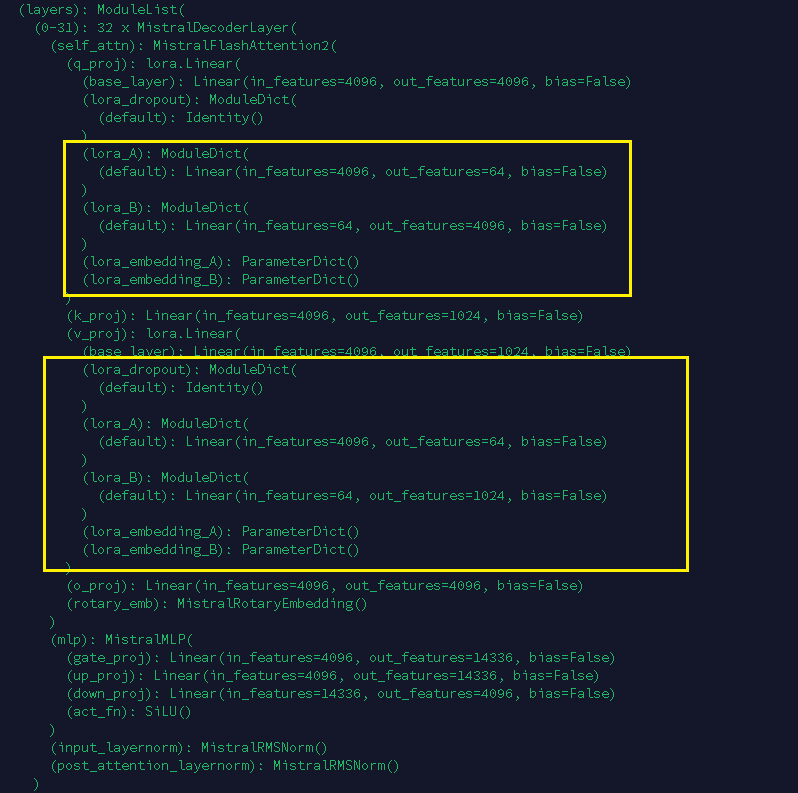
개인적으로는 이런식으로 저장하는 건 추천하지 않는다...
LoRA 의 강점 중 하나인 Pretrain Model 의 연산량과 동일하다는 특징을 없애버리는 형태다.
b. Model Weight 에 LoRA Matrix 를 더한 값을 저장
- Output : 모델 구조(=pytorch_model.bin)
- 특징
- Pretrain Model 과 구조가 동일하다.
- Model weight 값이 Pretrain Model weight 값과 다르다.
- LoRA layer 에 대한 정보는 저장되지 않는다. (알 수 없음)
- 본래 Pretrain Model 의 weight 로 원복 할 수 없다.
- Inference 시 Pretrain Model 의 연산량과 같다. (# of Model weight 가 완전 일치한다.)
- Pretrain Model 과 구조가 동일하다.
필자는 이 형태로 저장해서 사용하는 편이다.
본래 Pretrain Model 의 weight 로 원복할 수 없는 게 단점이 아닌가 싶을 수 있겠지만
본래 Pretrain Model 이 저장되어 있는데 원복이 왜 필요할까? 라는 생각 때문이다.
c. LoRA layer 만 따로 저장
- Output : LoRA layer 값이 저장된 하나의 bin 파일
- 특징
- 오직 LoRA layer 만 모여있는 weight 만 저장된다.
- 전체 Model 구조 및 weight 는 변경되지도 저장되지도 않는다.
- Inference 시 Pretrain Model 의 연산량과 같다. (# of Model weight 가 100% 일치한다.)
- Inference 시 먼저 Pretrain Model 과 병합을 하고 model.eval 을 진행한다.
- 즉, Inference 를 위해서는 Pretrain Model weight 에 LoRA Matrix 를 더하는 과정이 선행되어야 한다.
- 오직 LoRA layer 만 모여있는 weight 만 저장된다.
모델 구조를 보면 이렇게 되어있다.

이 방법도 괜찮다.
순위로 따지면 a, b, c 중에서 2순위 정도?
☞ 필자 생각에는 실험을 한다면 b > c > a 로 학습된 모델을 저장하는 게 좋다고 생각한다.
4. config setting

LoRA 학습 시 핵심이 되는 argument 값들이다.
- r : 행렬의 차원을 줄여 연산량을 최소화하기 위한 LoRA 의 dim 이다.
- lora_alpha : 이건 뭘까 수식을 봐야 이해될듯하다. 수식에 대한 이해가 귀찮으니 이런 문제가...
- lora_dropout : 학습 시 사용되는 dropout 확률 설정이다.
- target_modules : Model weight 에서 어디에 LoRA Matrix 를 더해줄지 설정할 수 있다.
- embedding layer, clm layer, decoder layer 에 있는 query, value 에 LoRA Matrix 를 더해줬다.
다시 언급하지만 target_modules 에서 몇 번째 decoder layer 에 LoRA Matrix 를 더해줄지를 선택하는 기능은 없다.
decoder layer 에 더해주고자 하는 LoRA Matrix 를 설정하면(ex. q_proj, v_proj, o_proj) 모든 decoder layer 에 적용된다.
마무리,,
지금까지 LoRA 에 대한 개념과 실제 학습할 때는 어떤 구조로 동작하는지, Output 은 어떠한지, config 설정은 무엇을 하는지를 알아봤다.
해당 내용은 실무자라면 궁금해할 만한 사항이라 생각한다.
왜냐하면 실무자가 궁금한 건 이론보다는 그래서 어떻게 동작하는데? 구조는 어떻게 되는데? 와 같이 실제 구동과 관련된 코드적인 내용이라 생각하기 때문이다.
사실 필자가 궁금한 게 저거라서 실무자라면 필자와 동일한 생각을 했을 거라 여겼다.
코드를 분석하면서 느낀 점이지만 이론도 알긴 해야 된다.
config 설정 시 argument 가 무엇을 의미하는지 모르겠다... ㅋㅋㅋ
아무쪼록 도움이 되었으면 좋겠다.




댓글