Sentence-Transformers (UKPlab)
Sentence embedding 관련 패키지 리서치 중 Sentence-Transformers Github 코드를 자세히 살펴볼 기회가 생겼다.
해당 패키지의 구조부터 자세한 상세 기능, 그리고 BERT 모델 사용 시 HuggingFace Transformers 와의 호환성까지 살펴보려 한다.
Sentence-Transformers 패키지 구조
📂sentence-transformers
|-📂cross_encoder
## output 형태가 Classifier layer에서 나오기 때문에 STS or NLI 학습 & 검증 용으로 사용
|-📄CrossEncode.py
|-📂datasets
## 학습 데이터셋을 관리하는 class
|-📄NoDuplicatesDataLoader.py
|-📄SentenceLabelDataset.py
...
|-📂evaluation
## 학습이 진행되는 동안 모델 검증을 하기 위해 정의되는 class
|-📄EmbeddingSimilarityEvaluator.py
### embedding 사이의 유사도를 gold label과 비교하여 Spearman & Pearson 상관 관계
### 계산을 통해 모델을 평가
|-📄MSEEvaluator.py
### 계산된 문장 임베딩과 일부 대상 문장 임베딩 사이의 평균 제곱 오차(x100)를 계산
|-📄LabelAccuracyEvaluator.py
### 레이블이 지정된 데이터 세트의 정확도를 기반으로 모델 평가
### LossFunction.SOFTMAX가 있는 모델이 필요 (Eval class 안에 SoftmaxLoss class 넣음)
...
|-📂losses
## 훈련 데이터에서 모델을 fine-tune 하는 데 사용할 수 있는 Loss function 정의
|-📄SoftmaxLoss.py
### NLI 데이터로 모델을 학습하기 위한 softmax loss
|-📄MultipleNegativesRankingLoss.py
### positive pairs만 있는 경우 사용하는 loss
|-📄CosineSimilarityLoss.py
### 두 sentences emb. 간의 cosine 유사성을 사용하여 gold label과 비교한 MSEloss
|-📄OnlineContrastiveLoss.py
### hard positive & hard negative 쌍에 대해서만 loss 계산. ConstrativeLoss와 비슷
### SiameseDistanceMetric class로 pos & neg 각각의 loss의 합을 최종 loss로 사용
...
|-📂models
## Model archi. 정의
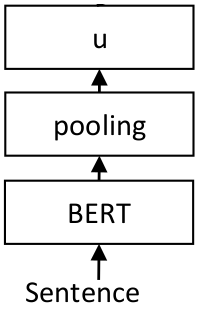
|-📄Transformers.py
### 토큰 임베딩을 생성하는 Huggingface AutoModel
|-📄Pooling.py
### 토큰 임베딩에서 Pooling(max or mean or etc...) 수행
|-📄Dense.py
### Feed-forward function with activiation function.
|-📄CNN.py
|-📄LSTM.py
|-📄WeightedLayerPooling.py
|-📄WordEmbedding.py
...
|-📂readers
## InputExample.py 외에는 관리되지 않는 것 같음. (main class에서 사용되지 않음)
## 직접 InputExample class 활용해서 데이터셋 구성 추천
|-📄NLIDataReader.py
|-📄STSDataReader.py
|-📄InputExample.py
...
|-📄SentenceTransformer.py
## Sentence-Transformers main class
|-class SentenceTransformer(nn.Sequential)
def __init__()
### model define, device setting
def encode()
### sentence embedding 계산
def tokenize()
### Tokenizes the texts
def fit()
### model 학습
def evaluate()
### model 검증
...
|-📄model_card_templates.py
## 데이터셋 및 loss를 포함한 모델 정보 print를 위한 script
|-📄util.py
## text embedding 작업에 유용한 다양한 기능 정의
Sentence-BERT Architecture
Comments
Sentence-Transformers 패키지 학습 Process는 좀 신기하게 구성되어져 있다...
관련된 자세한 사항은 추후 포스팅할 예정이다.
- 학습 Process
- 검증 및 예측 Process
- sentence-transformers 상세 기능
- HuggingFace transformers와 어떻게 다른지
To Be Continued.....
반응형
'Natural Language Processing > Github 훑어보기' 카테고리의 다른 글
| [Code review] Sentence-Transformers 비교 hug/trans (0) | 2022.07.08 |
|---|---|
| [Code review] Sentence-Transformers 상세 기능 (0) | 2022.07.08 |
| [Code review] Sentence-Transformers 검증 및 예측 Process (0) | 2022.07.06 |
| [Code review] Sentence-Transformers 학습 Process (0) | 2022.07.05 |



댓글